RAG 知识库
字数: 0 字 时长: 0 分钟
生成式 AI 的本质是 通过从大规模数据中学习潜在规律、创造出符合人类认知的、具有原创性的新内容,核心是学习数据的概率分布,是去猜测下一个要生成的内容,比如“苹果”之后出现“好吃”的概率要远高于“跑步”。因此,即使 AI 不知道如何回答我们提出的问题,也会尝试自圆其说地编造内容,有时候会给人一种“一本正经地胡说八道”的感觉。
那么如何让 AI 回答的内容更靠谱呢?这就需要用到 AI 主流的技术 --- RAG 。
什么是 RAG ?
RAG (Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和 AI 内容生成的混合架构,可以解决大模型的知识时效性和幻觉问题。
RAG 在 AI 大模型生成回答之前,会先从外部知识库检索相关信息,然后将这些检索到的内容作为额外上下文提供给模型,引导其生成更准确、更相关的回答。
通过 RAG 技术改造后, AI 大模型就能:
- 准确回答关于特定领域的问题,更专业(不再是泛化的通用知识)
- 在合适的时机回答特定内容(更个性化地定制内容)
- 用特定的语气和风格与用户交流
- 提供更新、更准确的建议(大模型知识受训练数据的时效性限制)
RAG 的工作流程
RAG 的实现主要包含以下 4 个核心步骤:
- 文档收集和切割
- 向量转换和存储
- 文档过滤和检索
- 查询增强和关联
1. 文档收集和切割
- 文档收集:从各种来源(网页、文件、数据库等)采集原始文档,比如下图的 markdown 文档

- 文档预处理:ETL 清洗为标准化文本格式,比如原文档被预处理为以下格式:
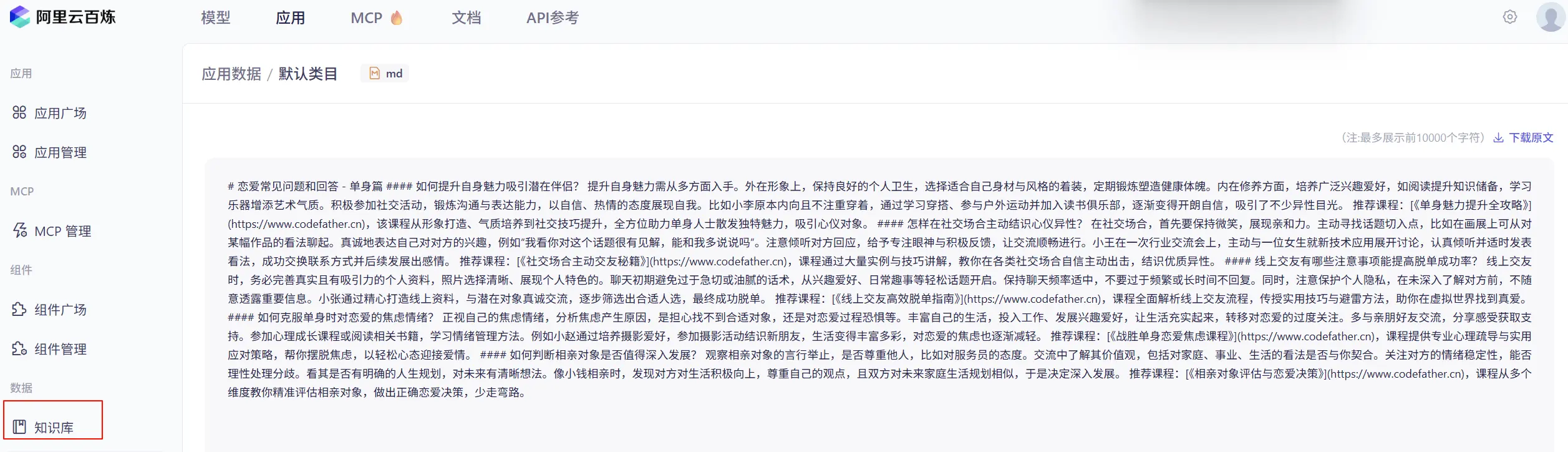
- 文档切割:基于固定大小、语义边界或递归策略等将长文档分割为适当大小的片段,比如原文档被分割为 3 个切片:
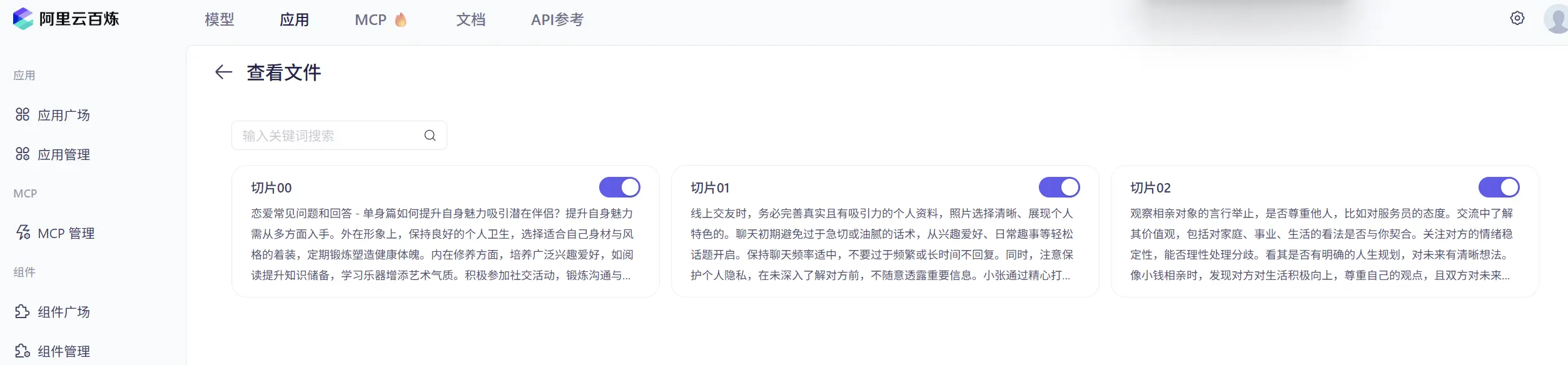
2. 向量转换和存储
- 向量转换:使用 Embedding 模型将文本块转换为高维向量表示,可以捕获文本的语义特征
- 向量存储:将生成的向量和对应文本存入向量数据库,支持高效的相似性搜索
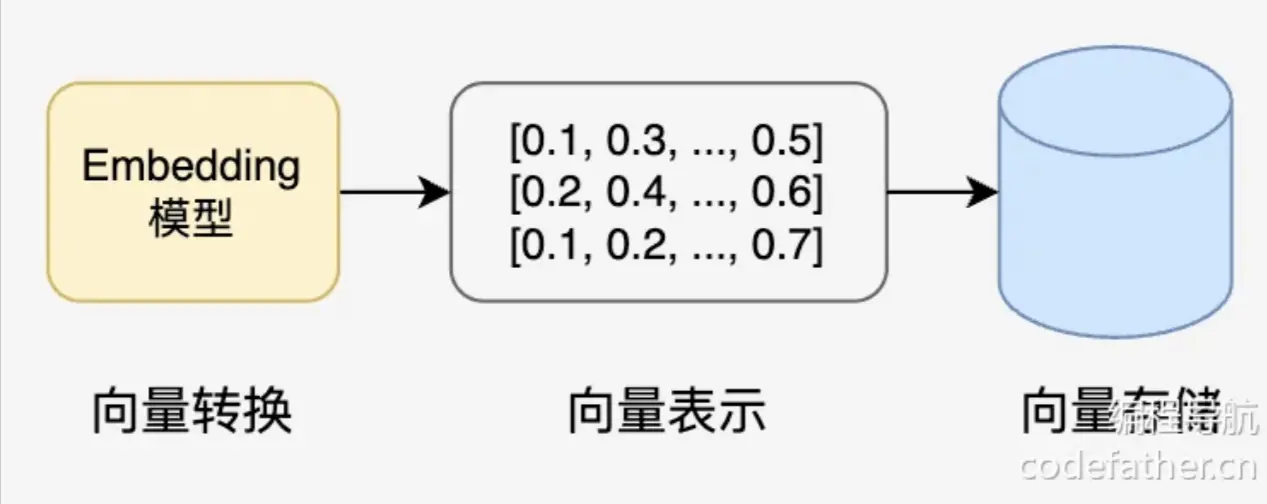
3. 文档过滤和检索
- 查询处理:将用户问题也转换为向量表示
- 过滤机制:基于元数据、关键字或自定义规则进行过滤
- 相似度搜索:在向量数据库中查找与问题向量最相似的文档块
- 上下文组装:将检索到的多个文档块组装成连贯上下文
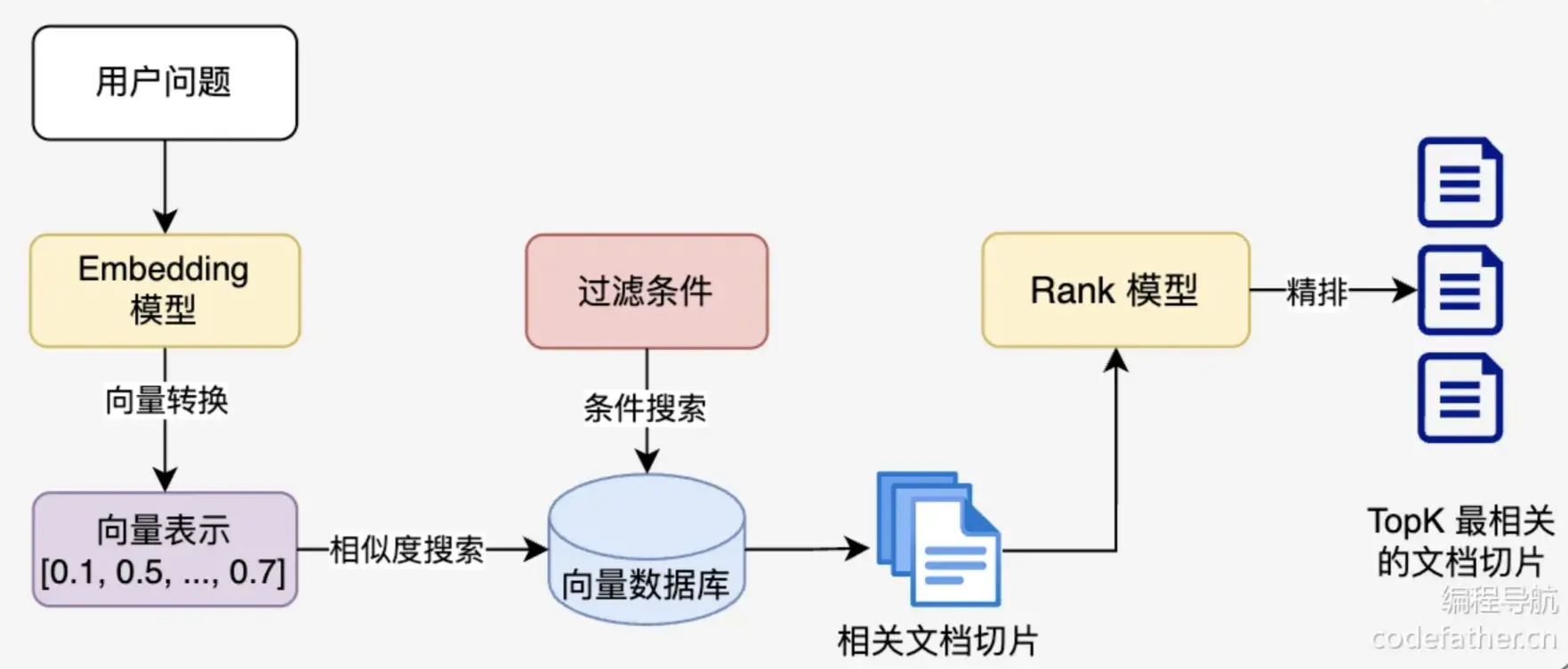
4. 查询增强和关联
- 提示词组装:将检索到的相关文档与用户问题组合为增强提示词
- 上下文融合:大模型基于增强提示生成回答
- 源引用:在回答中添加信息来源引用
- 后处理:格式化、摘要或其他处理以优化最终输出
RAG 检索增强完整工作流程如下:
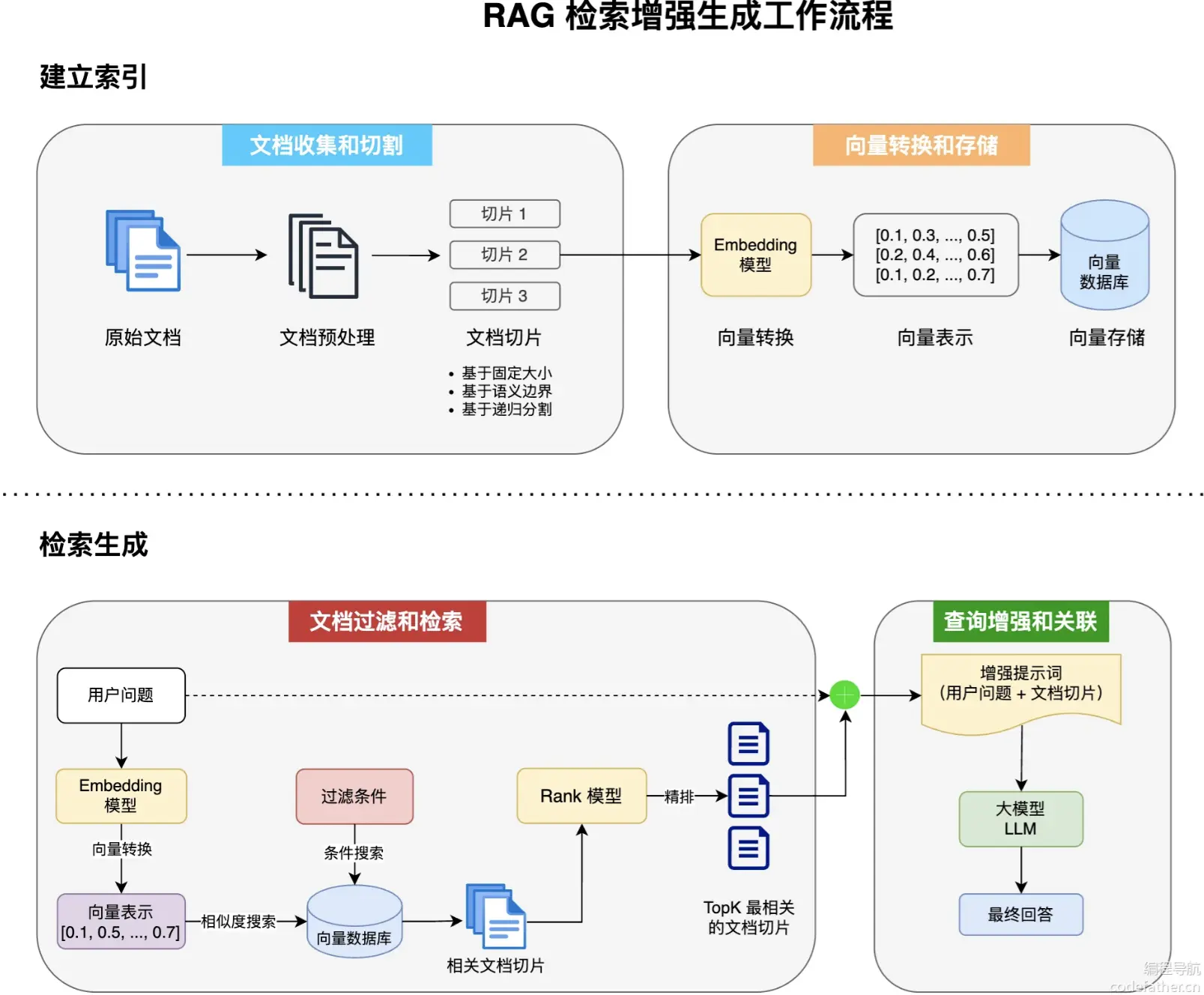
Spring AI 实现 RAG 原理
1. 文档收集与切割
RAG 第一步是将知识库文档进行收集处理并保存到向量数据库中,这个过程俗称 ETL (抽取、转换、加载)。Spring AI 使用三大组件来实现 ETL:
- 抽取:使用 DocumentReader 组件从数据源(如本地文档、网络资源、数据库等)加载文档
- 转换:使用 DocumentTransformer 组件将文档转换为适合后续处理的格式(比如去除冗余信息、分词、词性标注等)
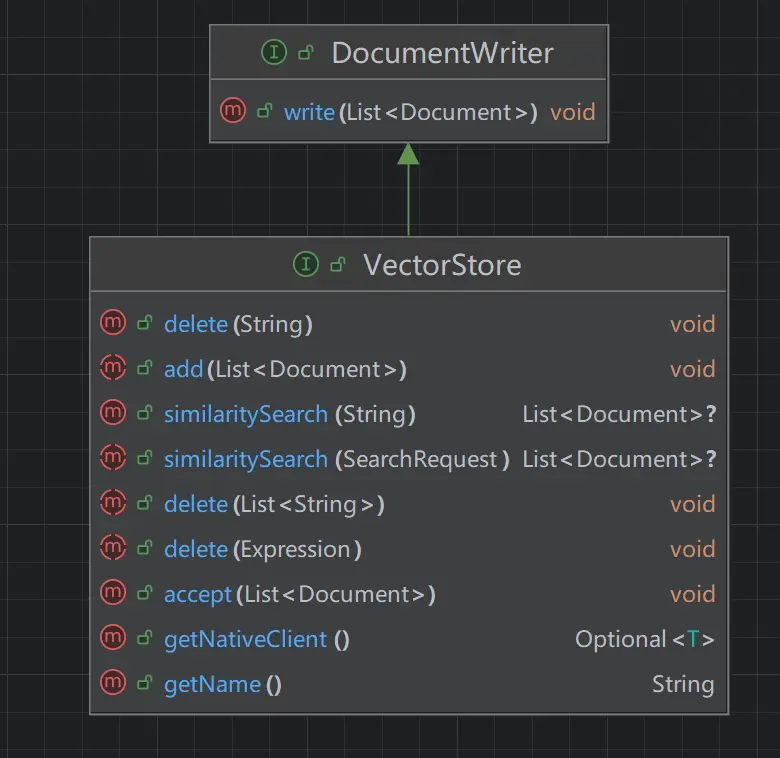
- 加载:使用 DocumentWriter 组件将文档以特定格式保存到存储中(比如将文档以向量的形式保存到向量数据库中)
1) DocumentReader
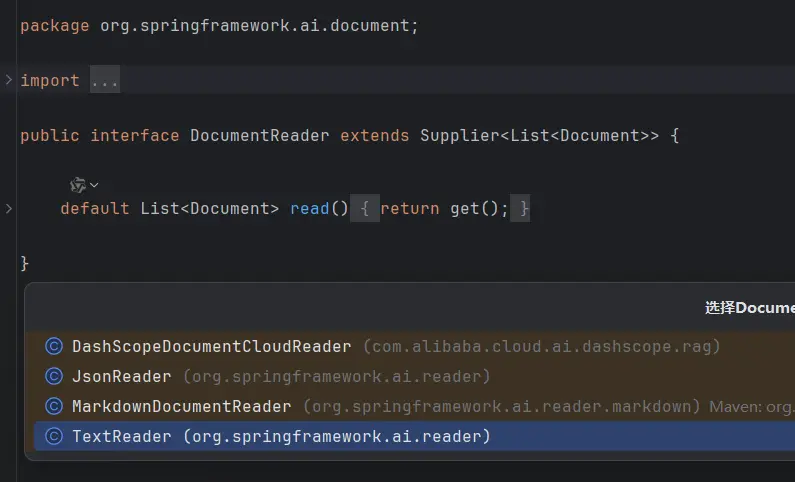
DocumentReader 接口主要负责从各种数据源读取数据并转换为 Document 集合,内置了多种实现,比如 MarkdownDocumentReader、JsonReader、PDFReader (需要引入相关依赖)
2)DocumentTransformer
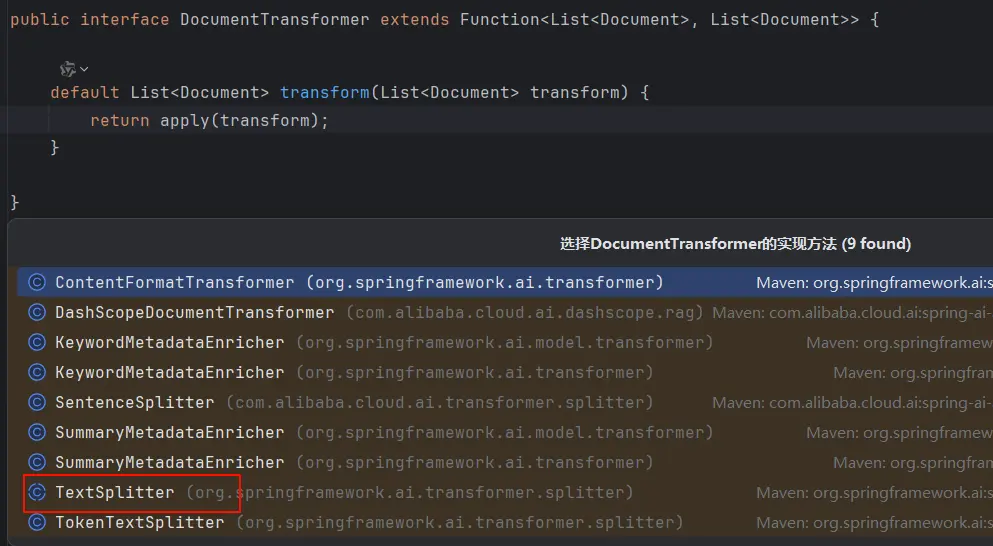
DocumentTransformer 接口负责将一组文档转换为另一组文档,比如去除冗余信息、分词等,是保证 RAG 效果的核心步骤,内置多种实现,比如:
- TextSplitter:文本分割器基类,提供了分割单词的流程方法
- TokenTextSplitter:基于 Token 的文本分割器,考虑了语义边界(比如句子结尾)来创建更有意义的文本段落
- KeywordMetadataEnricher:元数据增强器,使用 AI 提取关键词并添加到元数据中
- SummaryMetadataEnricher:使用 AI 生成文档摘要并添加到元数据中
3)DocumentWriter
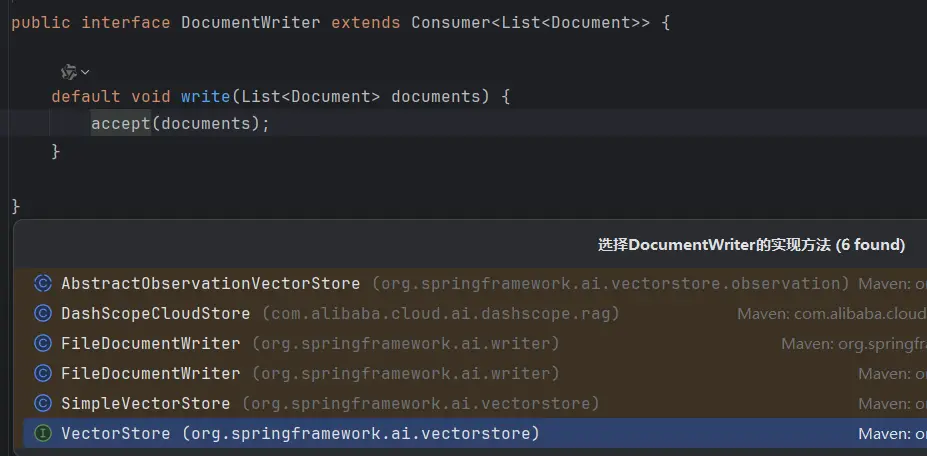
DocumentWriter 接口负责将 DocumentTransformer 处理后的文档写入到目标存储中,内置多种实现,比如:
- FileDocumentWriter:将文档写入到文件系统中
- VectorStore:将文档写入向量数据库中
2. 向量转换和存储
向量转换和存储指将文档转换为向量并存储到向量数据库中,Spring AI 提供了 VectorStore 向量数据库接口,帮助开发者快速集成各种第三方向量存储,如 Redis、PGVector、Elasticsearch 等
Spring AI 提供了 SearchRequest 类,用于构建相似度搜索:
SearchRequest request = SearchRequest.builder()
.query("如何维护长久的亲密关系?")
.topK(5) // 返回最相似的5个结果
.similarityThreshold(0.7) // 相似度阈值,0.0-1.0之间
.filterExpression("category == 'web' AND date > '2025-05-03'") // 过滤表达式
.build();
List<Document> results = vectorStore.similaritySearch(request);3. 文档过滤和检索
Spring AI 提供了一个 “模块化” 的 RAG 架构,用于优化大模型回复的准确性。简单来说,就是把整个文档过滤检索阶段拆分为:检索前、检索时、检索后三个阶段。
检索前
检索前优化用户的原始查询,以提高后续检索的质量,Spring AI 提供了多种查询预处理组件:
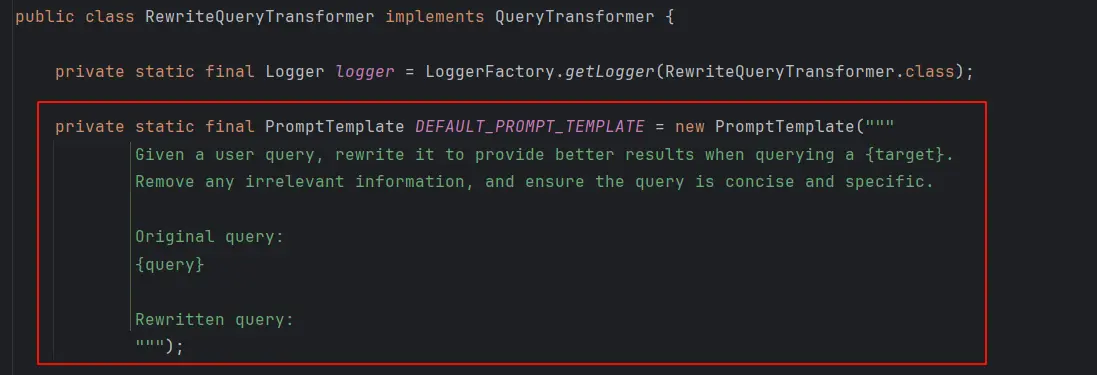
RewriteQueryTransformer使用大模型对用户的原始查询进行改写,使其更加清晰和详细。从源码中可以看到改写查询的提示词:
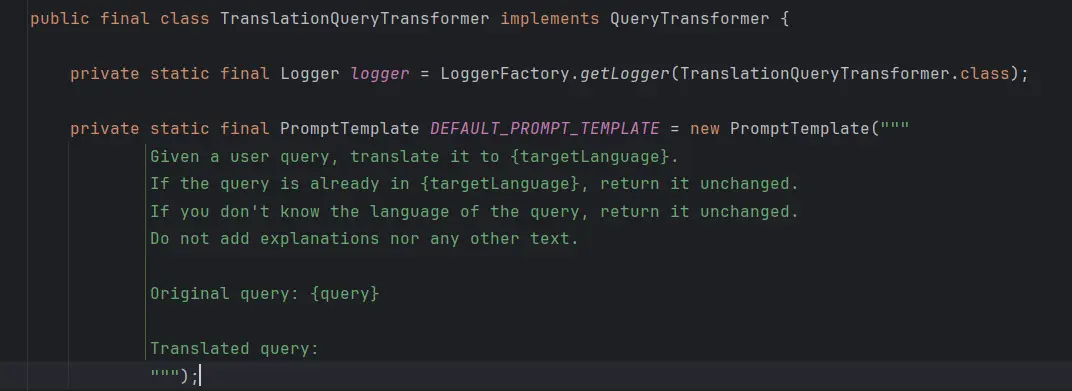
TranslationQueryTransformer将查询翻译成大模型支持的目标语言(比如中文翻译为英文),如果查询已经是目标语言,则保持不变
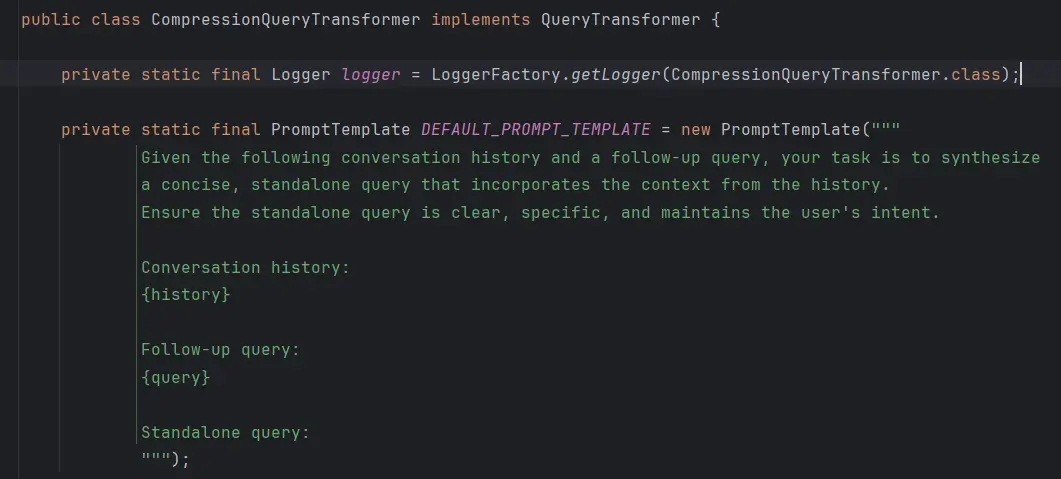
CompressionQueryTransformer使用大模型将对话历史和后续查询压缩成一个独立的查询,类似概括总结。适用于对话历史较长且后续查询与对话上下文相关的场景。
MultiQueryExpander查询扩展器,将原始查询扩展为多个相关查询,增加查询命中率
检索时
Spring AI 提供文档检索器 DocumentRetriever ,针对不同存储方式有不同实现,比如向量数据库的实现 VectorStoreDocumentRetriever,支持基于元数据的过滤、设置相似度阈值、设置返回的结果数等。
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore) // 指定向量数据库
.similarityThreshold(0.7) // 相似度阈值
.topK(5) // 最多返回 5 条结果
.filterExpression(new FilterExpressionBuilder() // 过滤表达式
.eq("type", "web")
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("如何摆脱单身!"));Spring AI 还内置了 ConcatenatedDocumentRetriever 文档合并器,可以将来自多个数据源检索到的文档(多个查询)合并为单个文档集合(自带去重)
Map<Query, List<List<Document>>> documentsForQuery = ...
DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();
List<Document> documents = documentJoiner.join(documentsForQuery);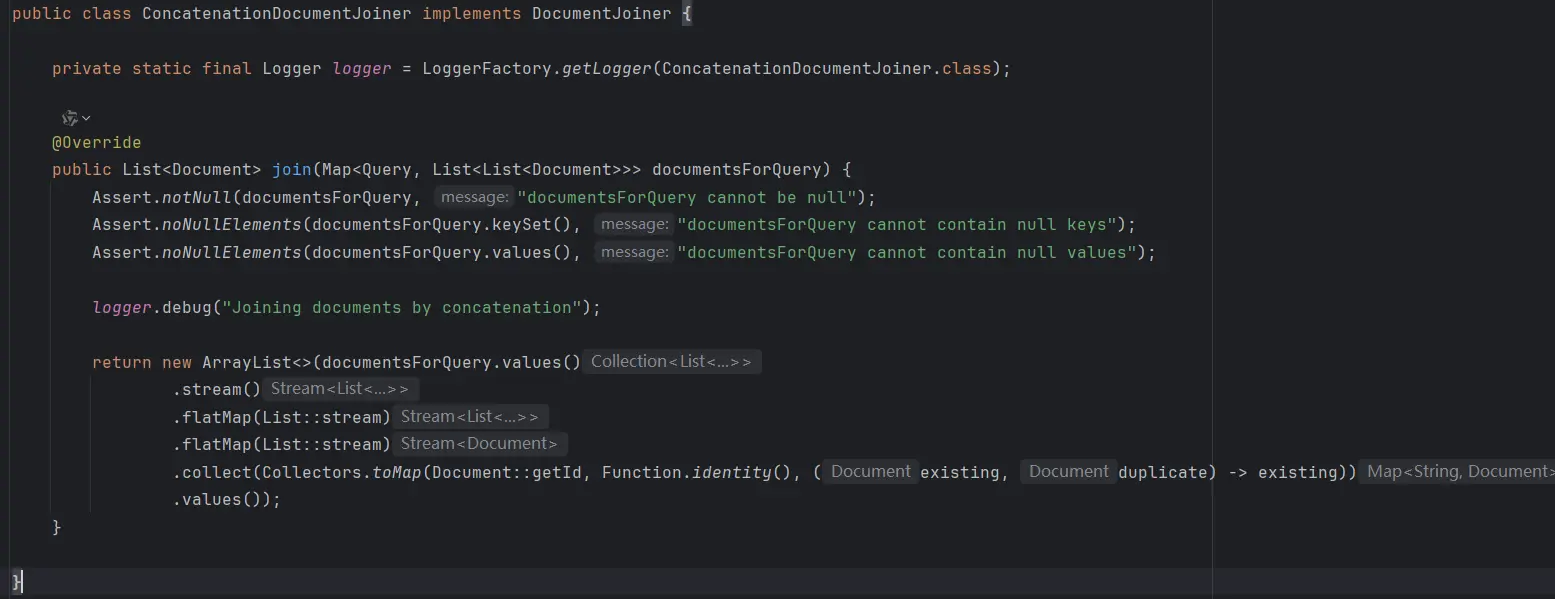
检索后
检索后模块负责处理检索到的文档,减少检索信息中的噪音和冗余,目前 Spring AI 支持较少,也不是实际开发中的重点。
4. 检索增强和关联
这个阶段是 RAG 流程的最终环节,负责将检索到的文档与用户查询结合起来,为 AI 提供必要的上下文,从而生成更准确、更相关的回答。Spring AI 提供了两种实现查询增强的 Advisor:
QuestionAnswerAdvisor查询增强,就是把用户提示词和检索到的文档等上下文信息拼成一个新的 Prompt,再调用 AI :
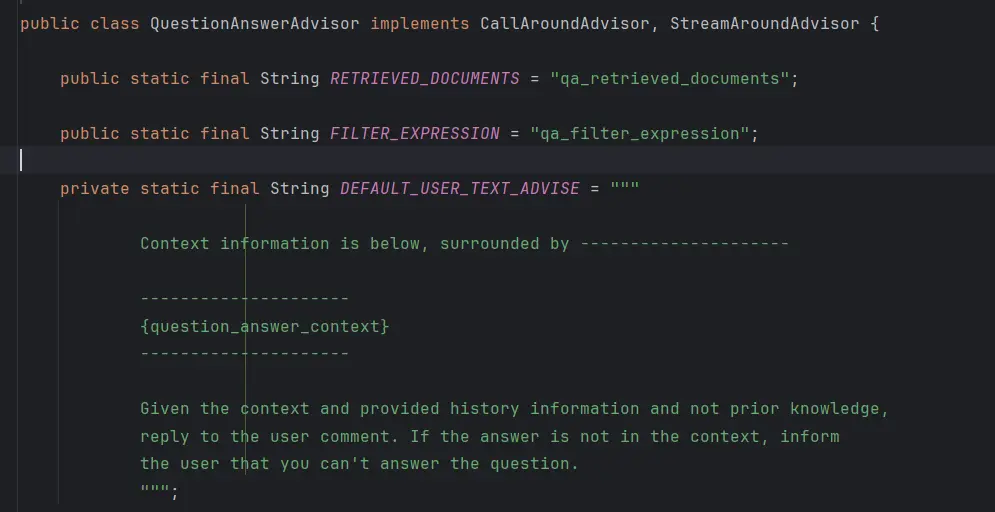
RetrievalAugmentationAdvisor基于 RAG 模块化架构,提供了更多灵活性和定制选项。最简单的 RAG 流程如下:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder() // 配置向量文档检索器
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();它还支持更高级的 RAG 流程,比如结合检索前的查询转换器:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.queryTransformers(RewriteQueryTransformer.builder() // 查询转换器改写用户原始查询
.chatClientBuilder(chatClientBuilder.build().mutate())
.build())
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();默认情况下, RetrievalAugmentationAdvisor 不允许检索的上下文为空,比如没有从 RAG 知识库检索到相关文档时,它会指示 AI 不要回答用户的问题。
这是一种保守策略,防止 AI 自己编回答,但某些场景即使知识库检索不到相关文档, AI 自己也有能力回答一些通用问题(比如 1 + 1 = 2),这种情况可以通过配置 ContextualQueryAugmenter 上下文增强器来实现.
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true) // 允许上下文为空
.build())
.build();为了提供更友好的错误处理机制,ContextualQueryAugmenter 允许用户自定义提示模板:
QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder()
.promptTemplate(customPromptTemplate) // 正常提示模板
.emptyContextPromptTemplate(emptyContextPromptTemplate) // 上下文为空的提示模板
.build();RAG 实战:Spring AI + 本地知识库
我们在本地准备三篇 markdown 文档模拟本地知识库场景:
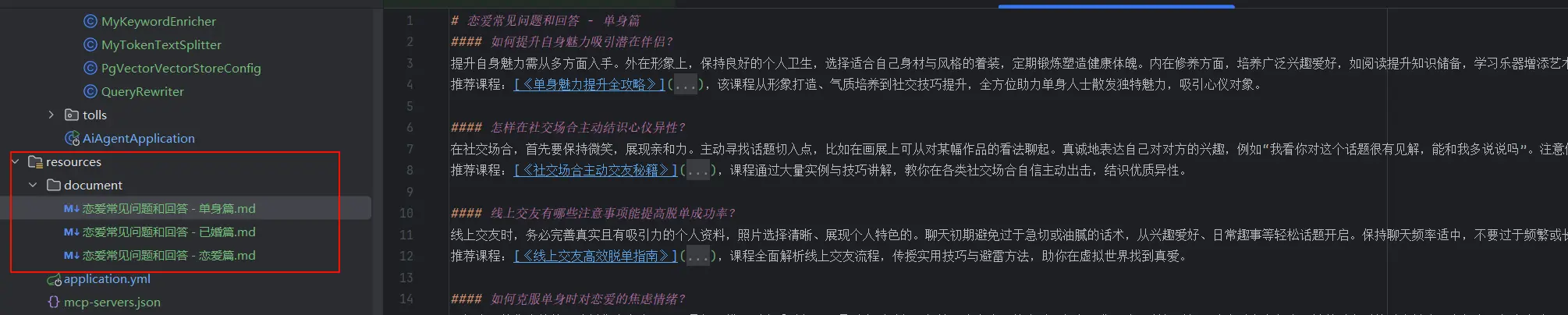
- 引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>1.0.0-M6</version>
</dependency>- 编写 Markdown 文档加载器
@Slf4j
@Component
public class LoveAppDocumentLoader {
private final ResourcePatternResolver resourcePatternResolver;
public LoveAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
public List<Document> loadMarkdowns() {
List<Document> allDocuments = new ArrayList<>();
try {
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
String filename = resource.getFilename();
String status = filename.substring(filename.length() - 6, filename.length() - 4);
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", filename)
.withAdditionalMetadata("status", status)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(reader.get());
}
}catch (Exception e) {
log.error("文档加载失败",e);
}
return allDocuments;
}
}- 初始化向量数据库
@Configuration
public class LoveAppVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();
// 加载文档
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
simpleVectorStore.add(documents);
return simpleVectorStore;
}
}- 使用更简单易用的
QuestionAnswerAdvisor问答拦截器实现检索增强
@Resource
private VectorStore loveAppVectorStore;
@Resource
private QueryRewriter queryRewriter;
public String doChatWithRag(String message,String chatId) {
// 查询重写
String rewriteMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient.prompt()
.user(rewriteMessage)
.advisors(advisorSpec -> advisorSpec
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
.advisors(new MyLoggerAdvisor())
// 本地 RAG 知识问答
.advisors(new QuestionAnswerAdvisor(loveAppVectorStore))
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}- 单元测试
通过 DEBUG 发现用户原始提示词 “我以及结婚了,但婚后关系不太亲密,怎么办?” 被改写为了 “已婚后关系不亲密,如何改善” 。说明查询重写功能已经成功。
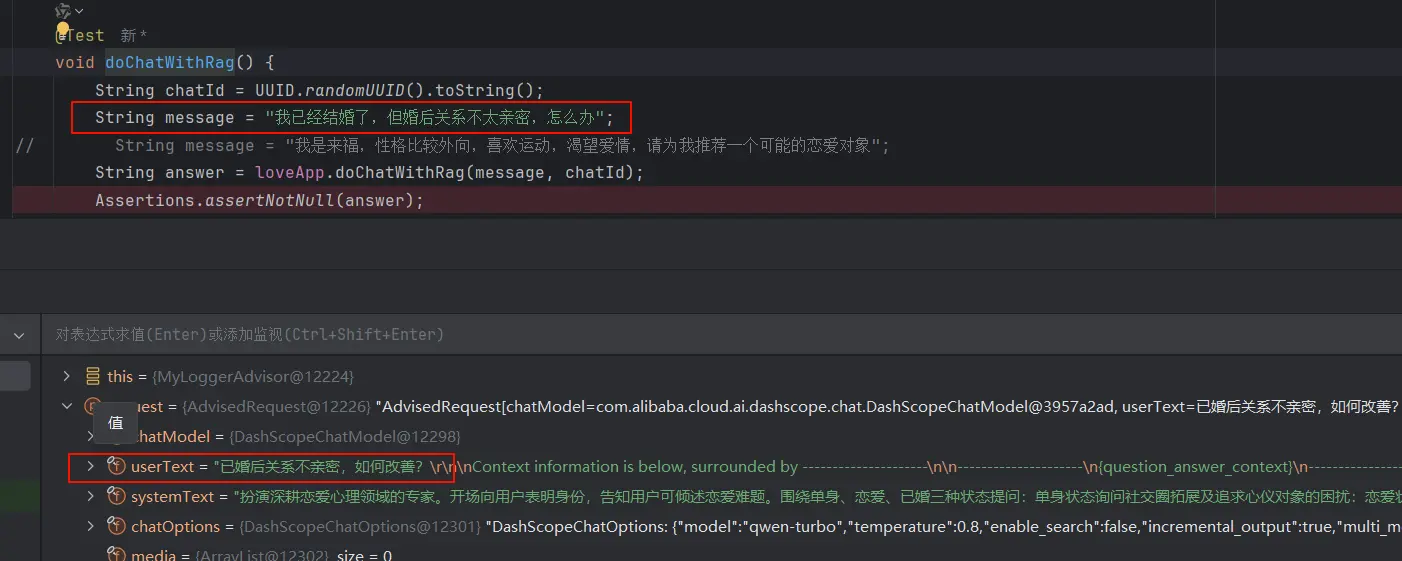
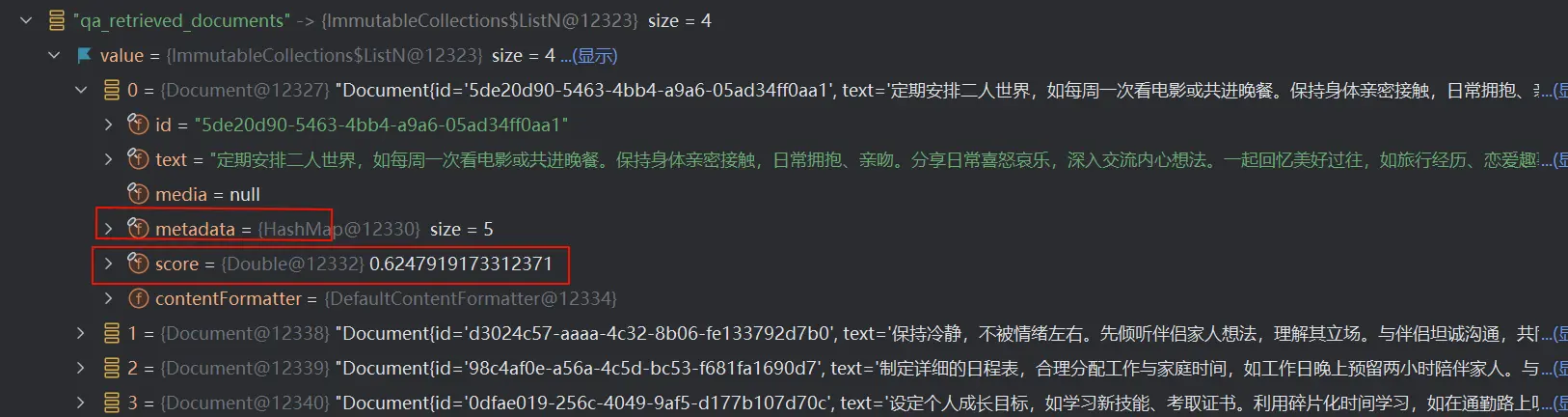
再查看 adviserContext 可以发现成功从本地 RAG 知识库中检索到了 4 个文档切片,并且每个文档切片有元信息和分数
RAG 实战:Spring AI + 云知识库
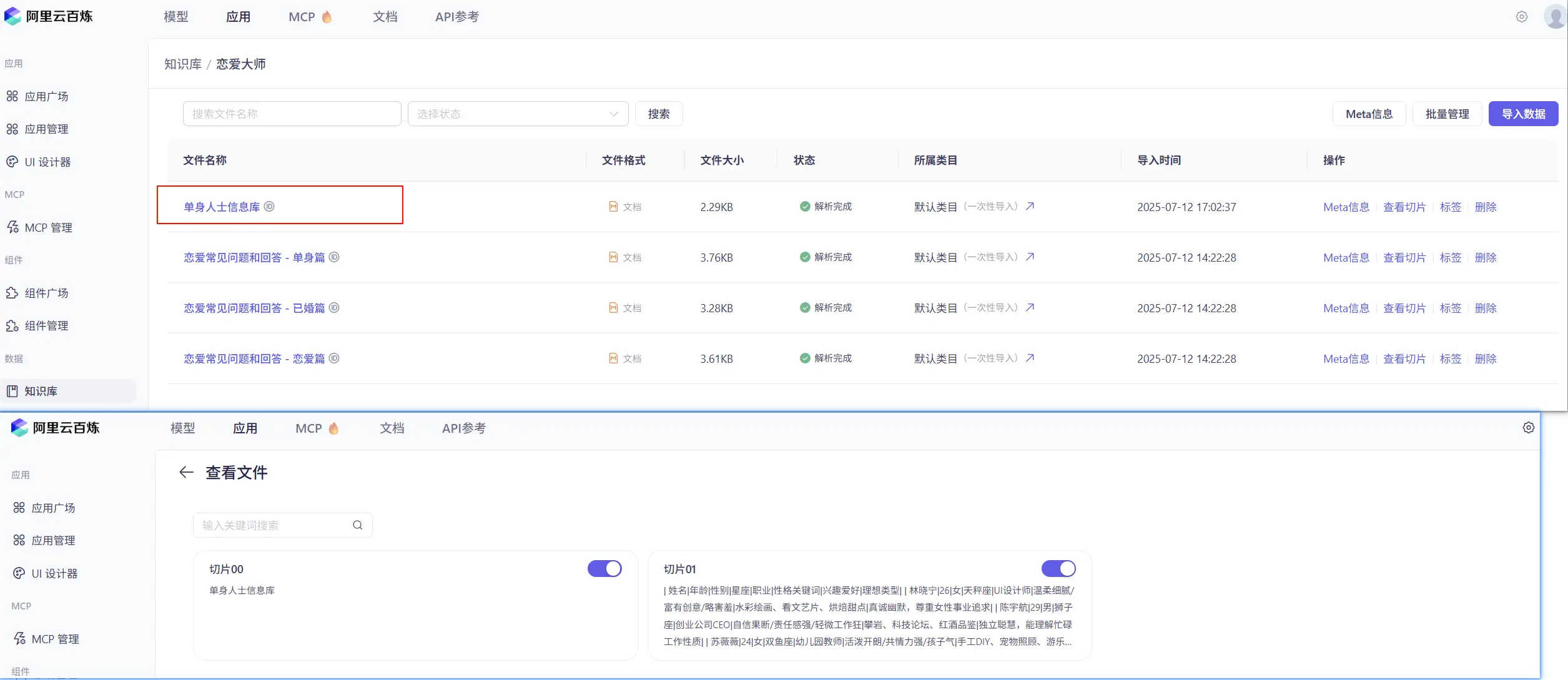
在阿里云百炼平台创建云知识库,这里我们上传一些单身人士信息,后续让 AI 为我们推荐潜在的相亲匹配对象。
- 使用
DashScopeApi接入阿里云知识库
/**
* 自定义基于 阿里云知识库的增强顾问
*/
@Configuration
public class LoveAppRagCloudAdvisorConfig {
@Value("${spring.ai.dashscope.api-key}")
private String dashScopeApiKey;
@Bean
public Advisor loveAppRagCloudAdvisor() {
DashScopeApi dashScopeApi = new DashScopeApi(dashScopeApiKey);
final String KNOWLEDGE_INDEX = "恋爱大师";
DashScopeDocumentRetriever dashScopeDocumentRetriever = new DashScopeDocumentRetriever(dashScopeApi,
DashScopeDocumentRetrieverOptions.builder()
.withIndexName(KNOWLEDGE_INDEX)
.build());
// 使用 RetrievalAugmentationAdvisor 检索增强顾问灵活定制 RAG 流程
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(dashScopeDocumentRetriever)
.build();
}
}- 启用云知识库 RAG 检索增强服务
@Resource
private Advisor loveAppRagCloudAdvisor;
public String doChatWithRag(String message,String chatId) {
ChatResponse chatResponse = chatClient.prompt()
.user(message)
.advisors(advisorSpec -> advisorSpec
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
.advisors(new MyLoggerAdvisor())
// 基于云知识库 RAG 检索增强服务
.advisors(loveAppRagCloudAdvisor)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}- 编写单元测试,发现 AI 根据我的个人信息为我从 RAG 知识库中推荐了一位最匹配的恋爱对象
