flink 容错机制
字数: 0 字 时长: 0 分钟
检查点
在流处理中,我们可用用存档读档的思路,将某个时间点所有的状态保存下来,这份存档就是 检查点。
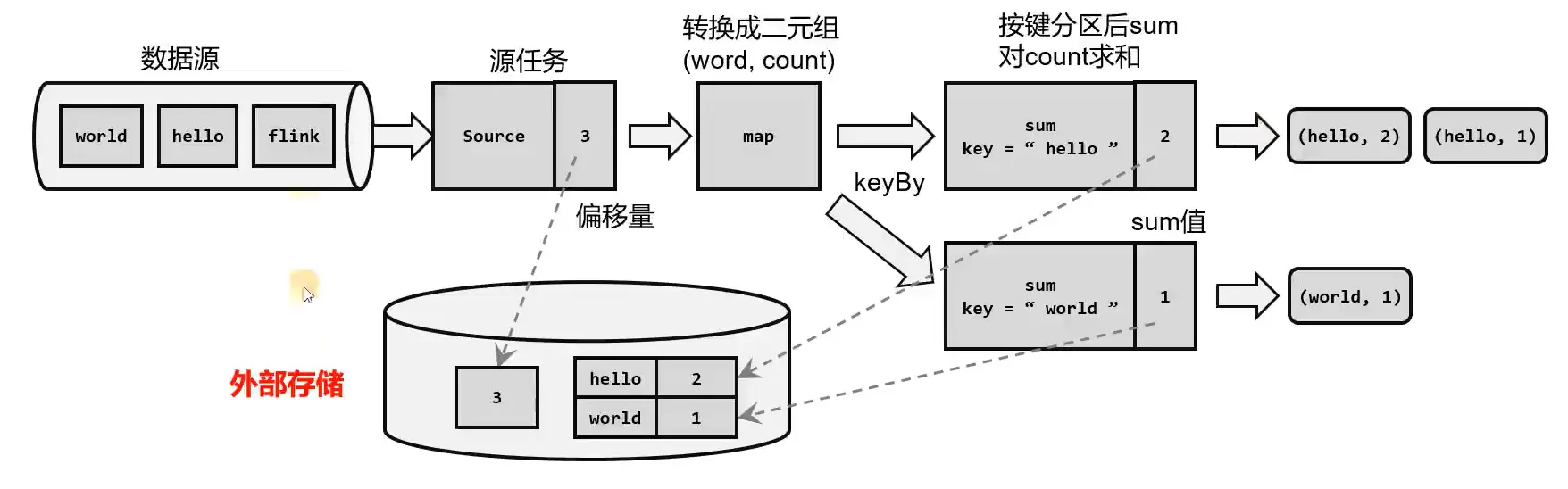
检查点的保存
在 Flink 中检查点的保存是周期性触发的,间隔时间可以进行设置。我们应该在所有任务(算子)都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。如果出现故障,我们只需要让源 (source) 任务向数据源重新提交偏移量、请求重放数据就可以了。这需要源任务把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量,比如 kafka
检查点算法
Flink 采用基于 Chandy-Lamport 算法的分布式快照,可以在不暂停整体流的前提下,将状态备份到检查点。
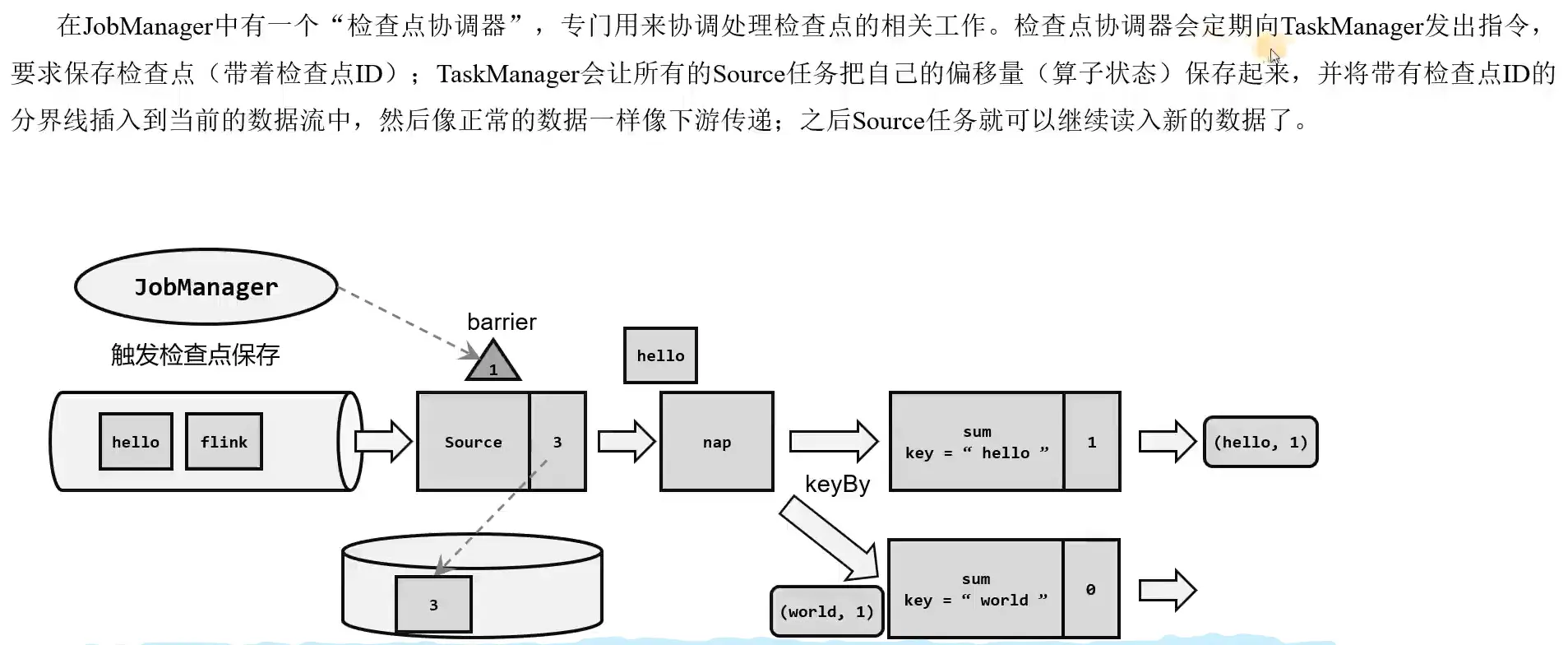
检查点分界线 Barrier
借鉴水位线的设计,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。收到保存检查点的指令后, Source 任务可以在当前数据流中插入这个结构; 之后的所有任务只要遇到它就开始对状态做持久化快照保存。
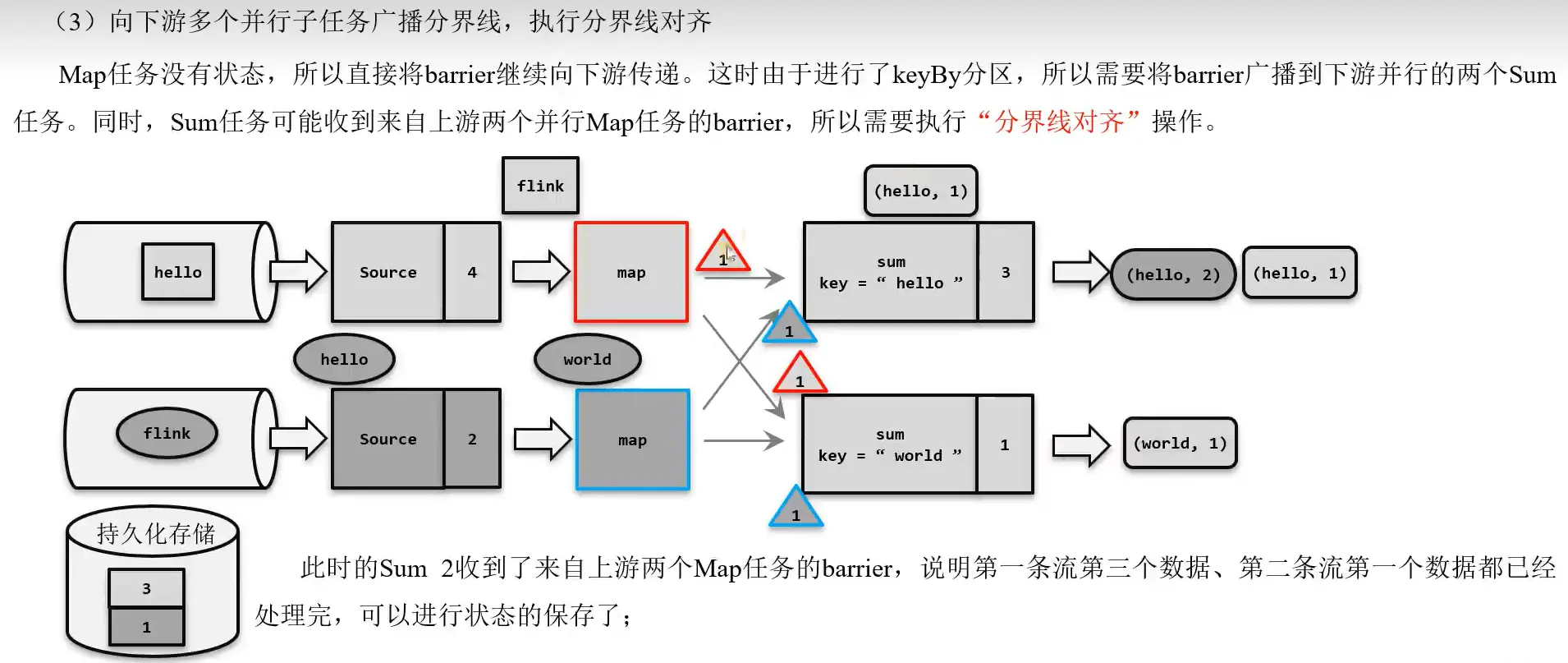
Barrier 对齐的精准一次
多并行度的情况下,比如 Map 下游两个子任务,那么就会产生多个 Barrier,此时需要将多个 Barrier 对齐,才能保证精确一次。如图所示, sum2 收到了 map1 和 map2 的 Barrier,然后保存状态;而 sum1 只收到 map2 的 Barrier,即使此时 sum1 收到了 map2 发送的 Barrier 之后的数据也不会处理,直到收到 map1 的 Barrier 之后保存状态之后才会继续处理数据。
Barrier 对齐的至少一次
Barrier 对齐的精准一次需要等待分界线对齐,这个过程可能会导致数据堆积,因此有另一种策略,就是在分界线对齐的过程中,允许继续处理 Barrier 之后的数据; 那么如果故障重启之后,会导致这部分 Barrier 之后的数据重复计算处理。
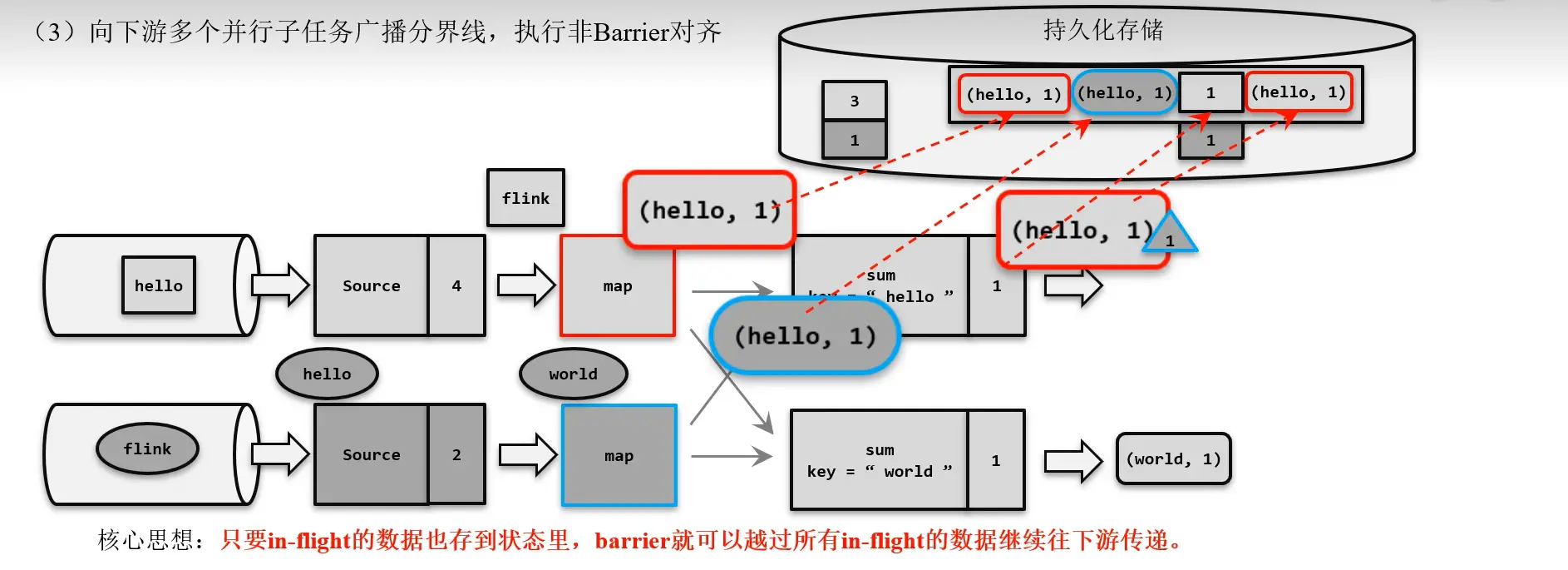
Barrier 非对齐的精准一次
Barrier 对齐的精准一次可能造成数据堆积,造成或加剧反压。因此,Flink 1.11 提供了非对齐的精确一次算法,如下图所示:当蓝色的 Barrier 到 sum1 的输入缓冲区时,就之间越过,到达 sum1 的输出缓冲区末端,并标记越过的数据和其他 Barrier 之后的数据,将这些标记的数据也一并存储在检查点中。