Flink 状态管理
字数: 0 字 时长: 0 分钟
在大数据流处理中,状态(State) 是实现复杂计算逻辑的关键,Flink 中的状态分为算子状态和键控状态:
- 算子状态(
Operator State)
算子状态是在算子层面持有和管理的状态,通常用在任务并行度相同、但要求状态在不同的并行实例中共享的场景。比如一个 Source 算子在适用 FlinkKafkaConsumer 读取数据时,可以将 Kafka 的 offset 信息存储在算子状态中,便于断点续读。
- 键控状态(
Keyed State)
键控状态是根据 key 进行管理的状态,通常在 keyBy 后的流中使用,每个 key 都可以有自己的状态。常见的类型有:
ValueState<T>:存储一个值ListState<T>:存储一个列表MapState<K,V>:存储一个 MapAggregatingState<IN,OUT>:适用于自定义的聚合操作ReducingState<T>:适用于累加操作
键控状态案
公共初始化代码
java
// 作业默认并行度设置为 1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 定义数据源 (nc 工具模拟数据流)
SingleOutputStreamOperator<WaterSensor> sensorDs = env.socketTextStream("8.140.207.120", 8081)
.map(new WaterSensorMapFunction())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((element, ts) -> element.getTs() * 1000L)
);1. 值状态
java
//todo 检测每种传感器的水位值,如果连续的两个水位值相差超过 10 , 就输出报警
sensorDs.keyBy(WaterSensor::getId)
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
//todo 1、定义一个状态,保存上一条数据的水位值
ValueState<Integer> lastVcState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//todo 2、在 open 方法中,初始化状态
lastVcState = getRuntimeContext()
.getState(new ValueStateDescriptor<Integer>("lastVcState", Types.INT));
}
@Override
public void processElement(WaterSensor value
, KeyedProcessFunction<String, WaterSensor
, String>.Context ctx, Collector<String> out) throws Exception {
// 1、取出上一条数据的水位值
int lastVc = lastVcState.value() == null ? 0 : lastVcState.value();
// 2、求差值的绝对值,判断是否超过 10
if (Math.abs(lastVc - value.getVc()) > 10) {
out.collect("传感器=" + value.getId() +"当前水位值=" + value.getVc() + ",与上一次的水位值=" + lastVc + ",超过10");
}
// 3、保存更新自己的水位值
lastVcState.update(value.getVc());
}
}
)
.print();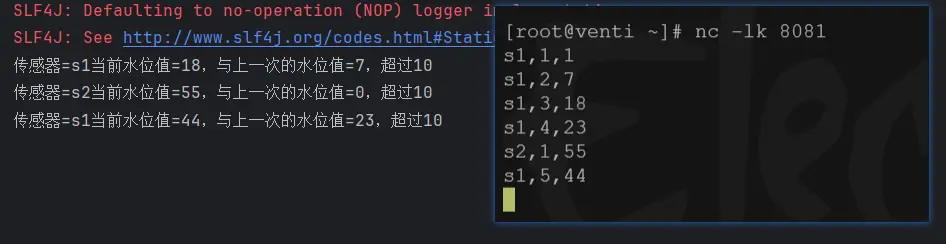
2. 列表状态
java
// 针对每种传感器输出最高的3个水位值
sensorDs.keyBy(WaterSensor::getId)
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
//todo 1、定义一个状态,保存数据的水位值,只保存最高的3个水位值即可
ListState<Integer> vcListState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcListState = getRuntimeContext().getListState(new ListStateDescriptor<Integer>("vcListState", Types.INT));
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
//1、来一条存到 list 状态里
vcListState.add(value.getVc());
//2、从 list 状态拿出来当前所有数据,拷贝到一个 list 中排序,只留 3 个最大的
Iterable<Integer> vcListIt = vcListState.get();
List<Integer> vcList = new ArrayList<>();
for (Integer i : vcListIt) {
vcList.add(i);
}
//3、排序
vcList.sort((o1, o2) -> o2 - o1);
//4、直留3个最大的
if (vcList.size() > 3) {
vcList.remove(3);
}
out.collect("传感器Id为:" + value.getId() + "最大的3个水位值=" + vcList.toString());
//5、更新状态保存留下来的数据
vcListState.update(vcList);
}
}
).print();
3. Map 状态
java
//todo 案例:统计每种传感器每种水位值出现的次数
sensorDs.keyBy(WaterSensor::getId)
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
MapState<Integer,Integer> vcCountMapState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcCountMapState = getRuntimeContext()
.getMapState(new MapStateDescriptor<Integer, Integer>("vcCountMapState", Types.INT, Types.INT));
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
//如果 vcCountMapState 包含 vc 对应的 Key
Integer vc = value.getVc();
if (vcCountMapState.contains(vc)) {
Integer count = vcCountMapState.get(vc);
vcCountMapState.put(vc,++count);
}else {
//如果不包含则初始化
vcCountMapState.put(vc,1);
}
//2、遍历 Map 状态,输出每个 k-v 的值
StringBuilder outStr = new StringBuilder();
outStr.append("传感器 id 为" + value.getId() + "\n");
for (Map.Entry<Integer, Integer> vcCount : vcCountMapState.entries()) {
outStr.append(vcCount.toString() + "\n");
}
outStr.append("==========================\n");
out.collect(outStr.toString());
}
}
).print();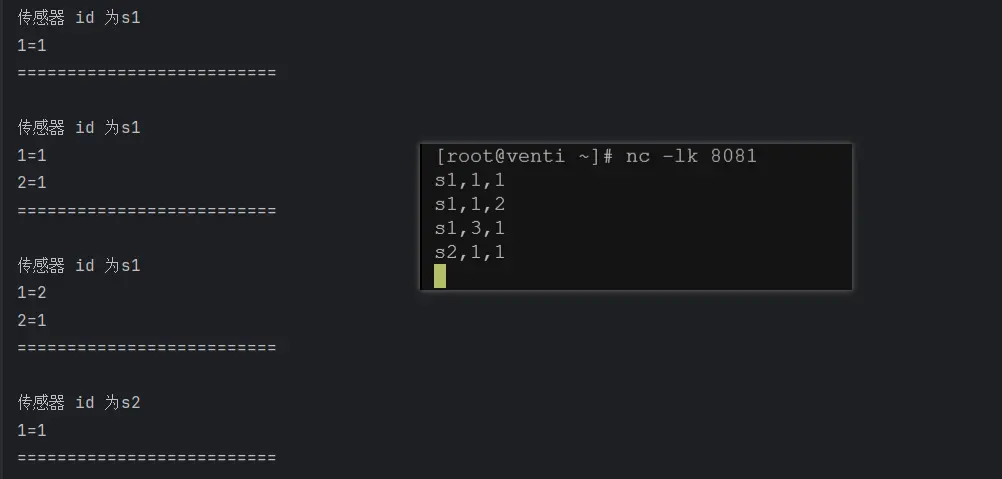
3. 规约状态
java
//todo 案例: 输出每个传感器的水位值总和
sensorDs.keyBy(WaterSensor::getId)
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
ReducingState<Integer> vcSumReducingState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcSumReducingState = getRuntimeContext()
.getReducingState(new ReducingStateDescriptor<Integer>("vcSumReducingState", Integer::sum, Types.INT));
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
vcSumReducingState.add(value.getVc());
Integer vcSum = vcSumReducingState.get();
out.collect("传感器 id 为" + value.getId() + ",水位值总和=" + vcSum);
}
}
).print();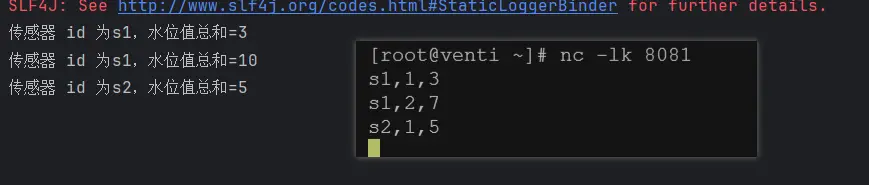
4. 聚合状态
java
// 输出每个传感器的水位值总和
sensorDs.keyBy(WaterSensor::getId)
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
// 将水位值添加到聚合状态中
vcAvgAggregatingState.add(value.getVc());
// 从聚合状态中获取结果
Double vcAvg = vcAvgAggregatingState.get();
out.collect("传感器id为:" + value.getId() + ",平均水位值=" + vcAvg);
}
AggregatingState<Integer,Double> vcAvgAggregatingState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcAvgAggregatingState = getRuntimeContext().getAggregatingState(
new AggregatingStateDescriptor<Integer, Tuple2<Integer,Integer>, Double>(
"vcAvgAggregatingState",
new AggregateFunction<Integer, Tuple2<Integer, Integer>, Double>() {
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0,0);
}
@Override
public Tuple2<Integer, Integer> add(Integer value, Tuple2<Integer, Integer> accumulator) {
return Tuple2.of(accumulator.f0 + value,accumulator.f1 + 1);
}
@Override
public Double getResult(Tuple2<Integer, Integer> accumulator) {
return accumulator.f0 * 1D / accumulator.f1;
}
@Override
public Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
return null;
}
},
Types.TUPLE(Types.INT, Types.INT)));
}
}
).print();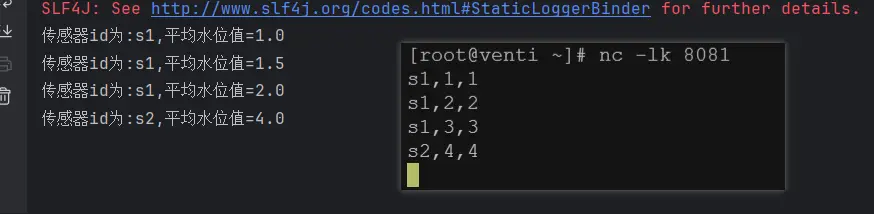
算子状态
1. 列表状态
在 map 算子中计算数据的个数
java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("8.140.207.120", 8081)
.map(new MyCountMapFunction())
.print();
env.execute();
}
//todo 1、实现 CheckpointedFunction
public static class MyCountMapFunction implements MapFunction<String,Long>, CheckpointedFunction {
private Long count = 0L;
private ListState<Long> state;
@Override
public Long map(String value) throws Exception {
return ++count;
}
/**
* //todo 2、本地变量持久化,将 本地变量 拷贝到 算子状态中,开启 checkpoint 时才会调用
* @param context the context for drawing a snapshot of the operator
* @throws Exception
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
System.out.println("snapshotState");
//2.1 清空算子状态
state.clear();
//2.2 将本地变量添加到算子状态中
state.add(count);
}
/**
* //todo 3、初始化本地变量,从状态中把数据添加到本地变量,每个子任务调用一次
* @param context the context for initializing the operator
* @throws Exception
*/
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
System.out.println("initializeState");
// 3.1 获取算子状态
state = context
.getOperatorStateStore()
.getListState(new ListStateDescriptor<Long>("state", Types.LONG));
/**
* 算子状态中 list 与 unionlist 的区别: 并行度改变后,怎么重新分配状态
* 1、list : 轮询分给新的并行子任务
* 2、unionlist : 原先多个子任务的状态合并成一份完整的,广播给每个新的子任务
*
*/
context.getOperatorStateStore()
.getUnionListState(new ListStateDescriptor<Long>("state2", Types.LONG));
// 3.2 从算子状态中把数据拷贝到本地变量
if (context.isRestored()) {
for (Long c : state.get()) {
count += c;
}
}
}
}2. 广播状态
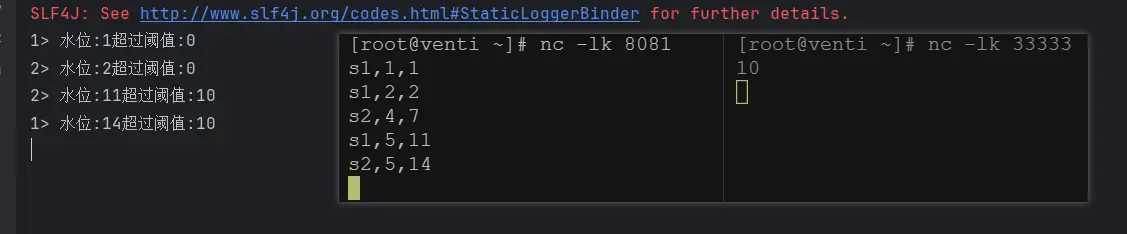
有时我们希望算子并行子任务都保持同一份“全局状态”,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样, 这种特殊的算子状态,就叫做广播状态。
java
//todo 水位超过指定的阈值发送告警,阈值可以动态修改
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
//数据流
SingleOutputStreamOperator<WaterSensor> sensorDs = env.socketTextStream("8.140.207.120", 8081)
.map(new WaterSensorMapFunction());
//配置流 用来广播配置
DataStreamSource<String> configDs = env.socketTextStream("8.140.207.120", 33333);
//todo 1、将配置流 广播
MapStateDescriptor<String, Integer> broadcastMapState = new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT);
BroadcastStream<String> configBS = configDs.broadcast(broadcastMapState);
//todo 2、将 数据流 和 广播后的配置流 连接起来
BroadcastConnectedStream<WaterSensor, String> sensorBCS = sensorDs.connect(configBS);
//todo 3、调用 process
sensorBCS.process(
new BroadcastProcessFunction<WaterSensor, String, String>() {
@Override
public void processElement(WaterSensor value, BroadcastProcessFunction<WaterSensor, String, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {
// todo 5、通过上下文获取广播状态,取出里面的值(只读,不可修改)
ReadOnlyBroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
Integer threshold = broadcastState.get("threshold");
//判断广播状态里是否有数据
threshold = (threshold == null ? 0 : threshold);
if (value.getVc() > threshold) {
out.collect("水位:"+ value.getVc() + "超过阈值:" + threshold);
}
}
//广播后的配置流的处理方法
@Override
public void processBroadcastElement(String value, BroadcastProcessFunction<WaterSensor, String, String>.Context ctx, Collector<String> out) throws Exception {
//todo 4、通过上下文获取广播状态,往里面写数据
BroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
broadcastState.put("threshold", Integer.valueOf(value));
}
}
).print();
env.execute();
}
状态后端
FLink 中状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫做状态后端。状态后端主要管理本地状态的存储方式和位置
- HashMapStateBackend
内存计算,读写速度非常块,但是状态大小受限于集群可用内存,如果应用状态不断增长,可能耗尽内存资源,是flink 的默认配置状态后端
- RocksDBStateBackend
硬盘存储,适合海量级状态存储,但是读写速度慢,状态大小无限制,但是需要集群可用磁盘空间