JUC 并发容器
字数: 0 字 时长: 0 分钟
ConcurrentHashMap
ConcurrentHshMap 是 JUC 中最核心也是最常用的并发容器。
- JDK 1.7 基于
Segment+ReentrantLock的分段锁实现。整个 Map 被分成固定数量的段,每个段本质上是一个小的Hashtable,拥有自己的锁(ReentrantLock)。 并发度固定(段的个数),锁粒度为段(同一个段里有多个 Key,仍然存在锁竞争可能性)。 - JDK 1.8 类似
HashMap采用Node[]+红黑树的设计,使用 CAS 和synchronized控制并发访问。
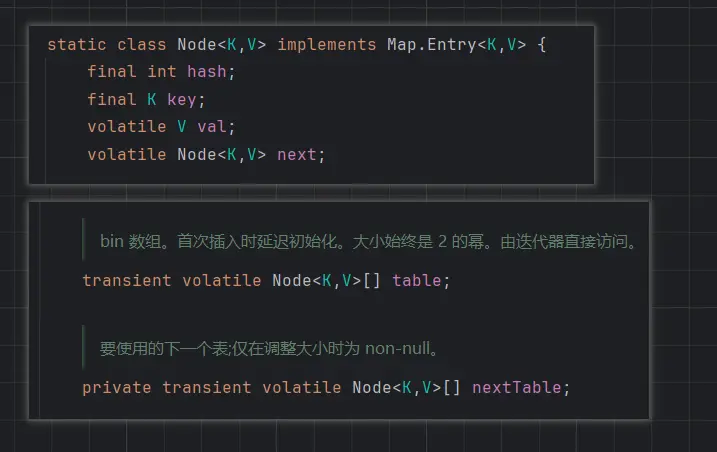
volatile 保证可见性
注意看,源码中 Node 节点的 V 和指向下一个链表节点的 next 都使用 volatile 保证可见性
无锁读 (volatile read)
通过 get() 源码可以发现,整个流程是无锁的,使用原子操作 tabAt 读取数组元素,其底层实现是调用 Unsafe 类中的 getReferenceVolatile(Object o, long offset)。
public V get(Object key) {
Node<K,V>[] tab; //哈希表数组
Node<K,V> e, p; // e:当前节点 p:临时节点,用于处理红黑树情况
int n, eh; // n:哈希表长度 eh:节点的哈希值
K ek; // ek 节点的键
// 对键的原始哈希值进行再散列,减少哈希冲突。并强制结果为正数(负数有特殊含义)
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 检测头节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 哈希值为负数(说明可能是红黑树或扩容)
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍历链表找到匹配的值
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}写操作核心流程
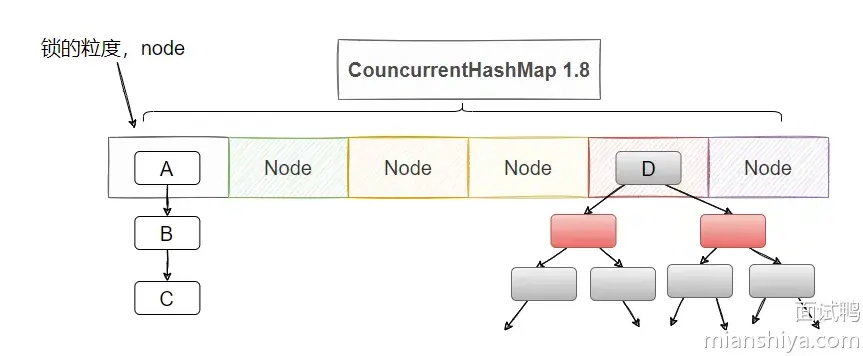
ConcurrentHashMap 以桶节点为单位使用 synchronized 加锁,当数组扩容时,并发度也会增加。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 1. 计算哈希值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
// 2. 桶为空时,CAS 创建节点
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 3. 桶不为空,则 tabAt 原子操作获取数组元素
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// CAS 成功则退出
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// 4. 检测到扩容则进行协助
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
// 5. 如果计算到的下标处已经有 Node,则加锁
// 这样别的线程就无法访问这个 Node 及其之后的所有节点
else {
V oldVal = null;
synchronized (f) { // 加锁 (锁粒度细化到单个桶)
if (tabAt(tab, i) == f) { // 再次 volatile 操作校验
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
// .... 红黑树相关
}
}
}
}
// 7. 更新计数并检查扩容
addCount(1L, binCount);
return null;
}JDK 1.7 和 JDK 1.8+ 扩容的区别
JDK 1.7:
ConcurrentHashMap由多个Segment组成,每个Segment中包含一个HashMap。 当某个Segment内的HashMap达到扩容阈值时,单独为该Segment扩容,不会影响其他Segment。JDK 1.8:取消了
Segment设计,改为类似HashMap的全局哈希桶数组。扩容时通过 CAS 操作保证线程安全, 并且在扩容时会多线程进来会触发协助扩容机制(每个线程通过 CAS 操作去搬运一部分数据)。
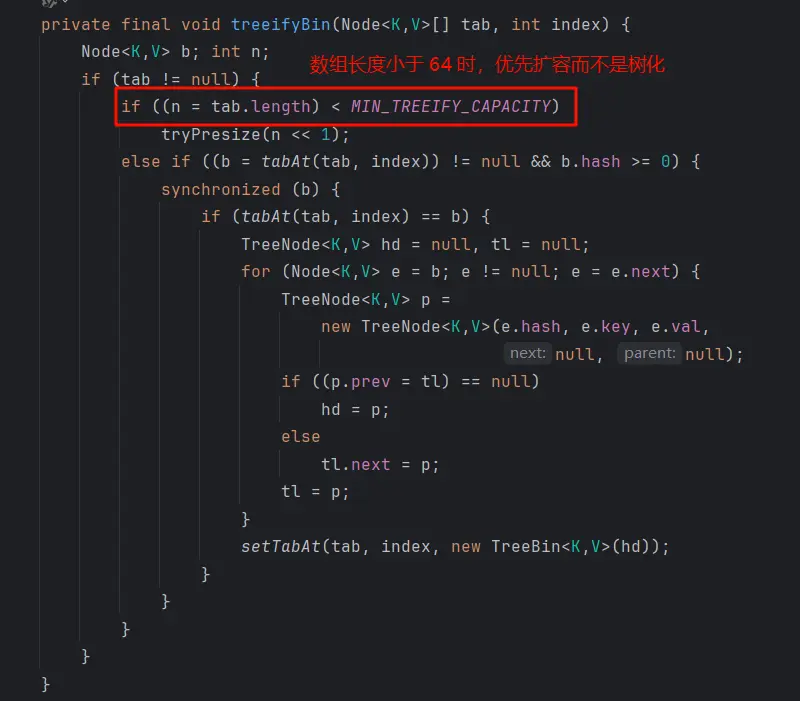
树化条件
CopyOnWriteArrayList
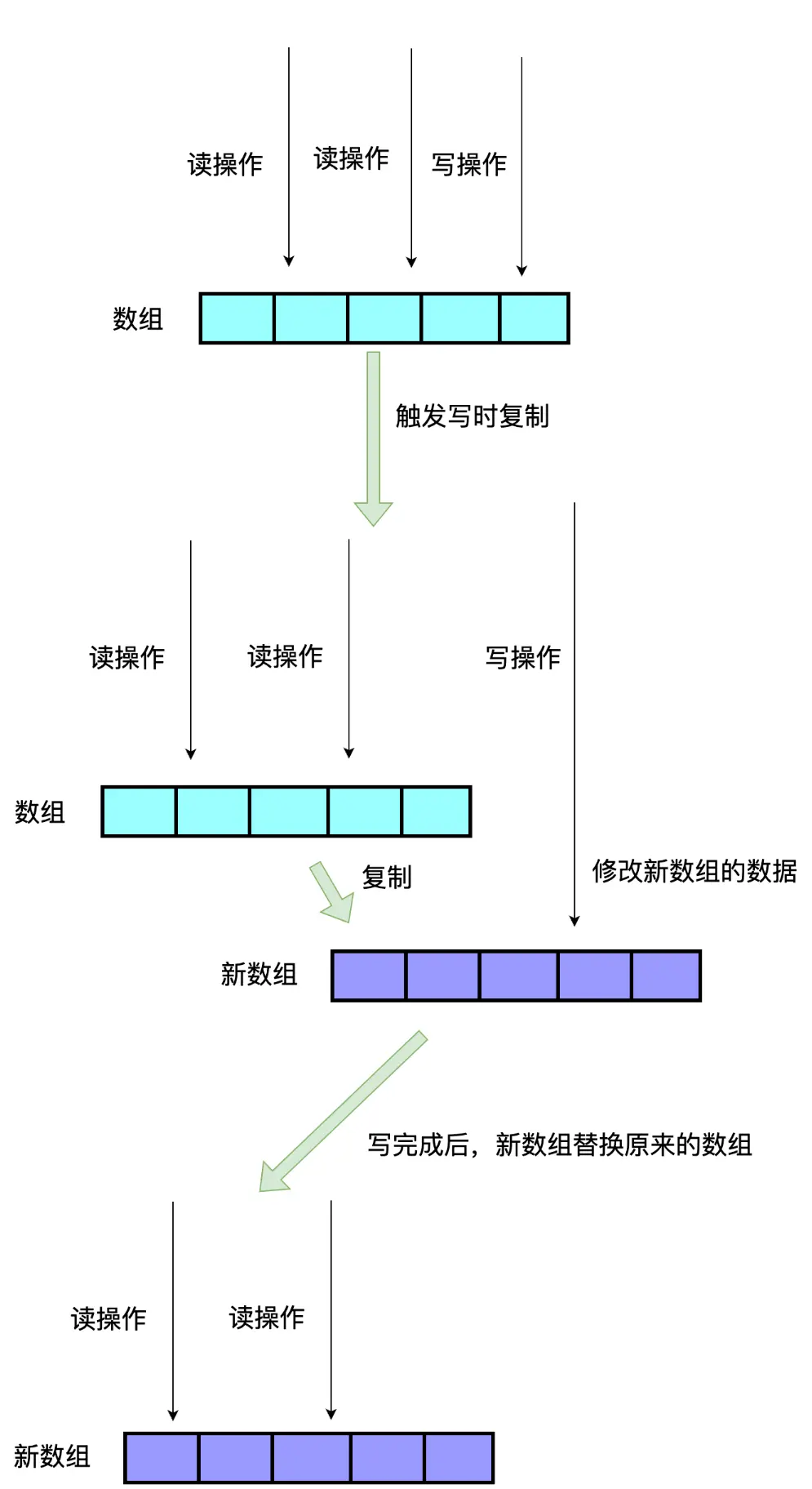
CopyOnWriteArrayList 是线程安全的动态数组,核心思想是写时复制(Copy-On-Write)。即在每次写入操作时,复制原始数组的内容保证线程安全,所以它的写操作开销大,读操作完全无锁,适合读多写少的场景
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private transient volatile Object[] array;
//写操作加锁
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 复制数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
// 替换原始数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
//读操作
private E get(Object[] a, int index) {
return (E) a[index];
}
}非阻塞队列
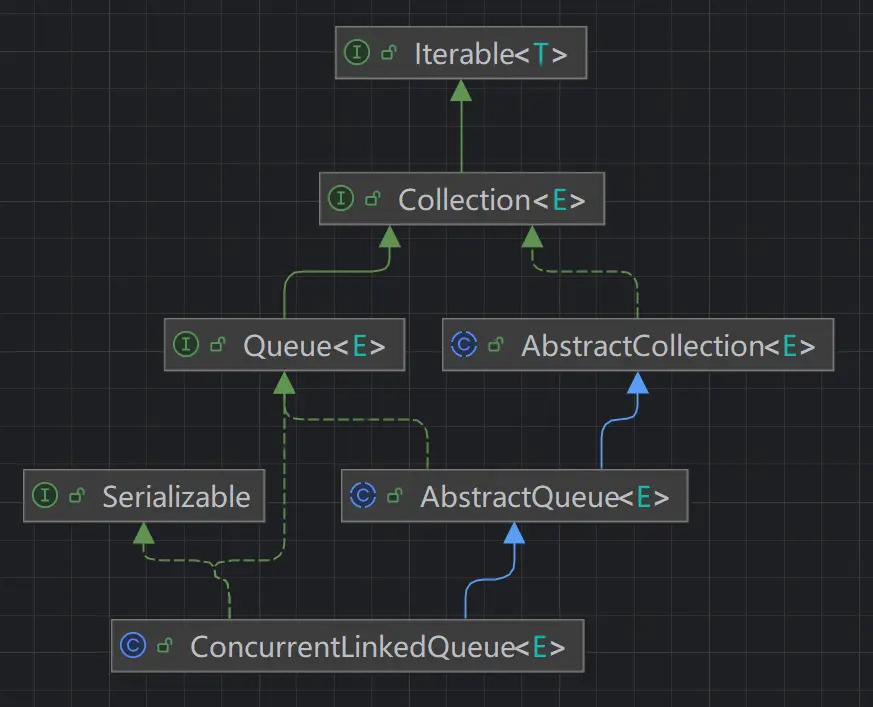
ConcurrentLinkedQueue
ConcurrentLinkedQueue 是一个基于 CAS 实现的线程安全无界队列,它采用先进先出的规则对节点进行排序
阻塞队列
阻塞队列 (BlockingQueue)相对于非阻塞队列,它提供了两个附加方法
- 阻塞插入
put(e):当队列满时,队列会阻塞插入元素的线程,直到队列不满 - 阻塞移除
take():当队列为空时,获取元素的线程会等待队列变为非空
ArrayBlockingQueue / LinkedBlockingQueue
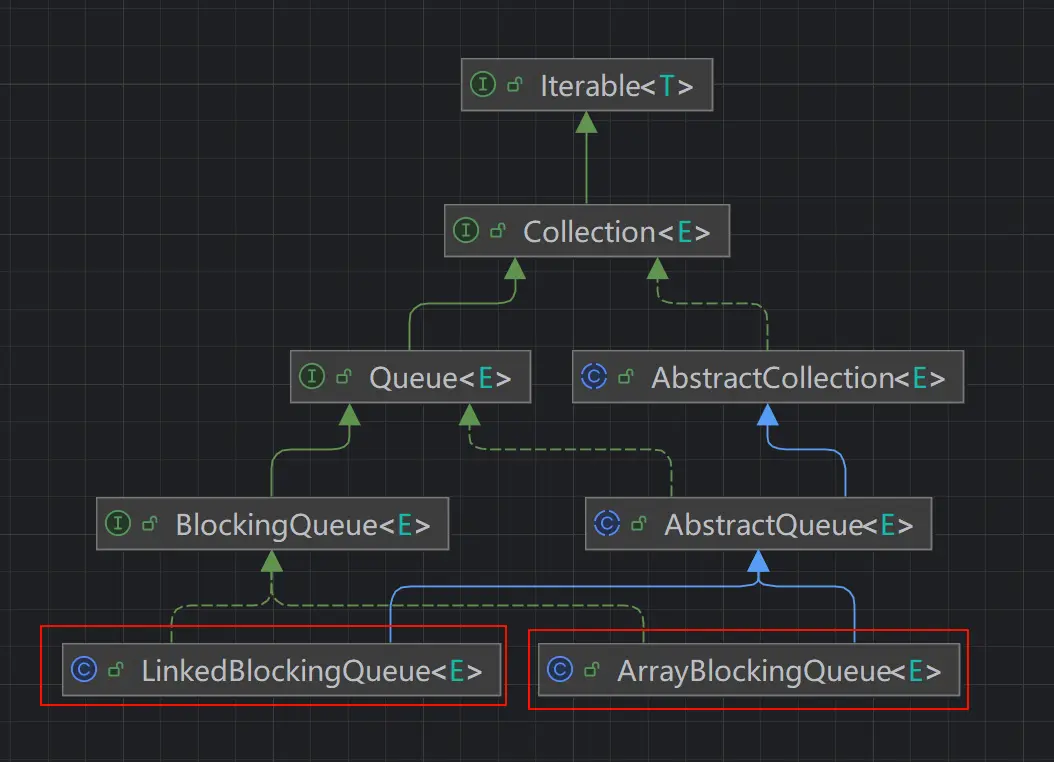
ArrayBlockingQueue 与 LinkedBlockingQueue 都是先进先出的有界阻塞队列,区别在于一个基于数组实现,一个基于链表实现。不过 LinkedBlokingQueue 也可以作为无界阻塞队列使用
LinkedBlockingQueue采用两把锁(锁粒度更低),高并发吞吐量更大
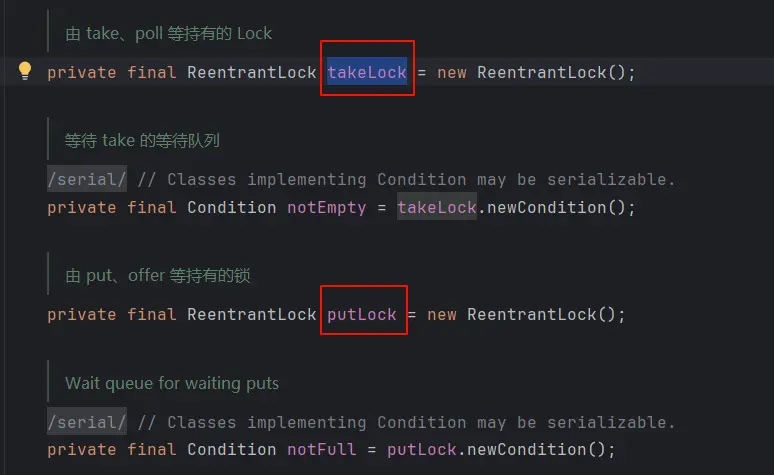
ArrayLinkedBlockingQueue采用一把锁,即全局锁,高并发场景这可能成为其性能瓶颈

PriorityBlockingQueue
PriorityBlockingQueue 是一个支持优先级的无界阻塞队列。默认情况下采用自然顺序升序排列。
- 可以自定义类实现
compareTo()来指定元素排列规则; - 也可以初始化
PriorityBlockingQueue时指定构造参数Comparator来对元素进行排序
DelayQueue
DelayQueue 是一个支持延时获取元素的无界阻塞队列,适用于定时任务、缓存失效等场景。但实际应用有限,比如缓存实际都使用成熟的缓存轮子,定时任务使用 ScheduledExecutorService
SynchronousQueue
SynchronousQueue 是一个不存储元素的阻塞队列,每一个添加 put 操作必须等待一个移除 take 操作,否则不能继续添加元素(类似传球手角色)。cachedThreadPool 使用的是 SynchronousQueue,适合 1:1 直接任务传递,是特定场景的性能王者。
LinkedBlockingDeque
LinkedBlockingDeque 是对 LinkedBlockingQueue 的一个补充,支持双向存取。