线程池
字数: 0 字 时长: 0 分钟
线程池原理
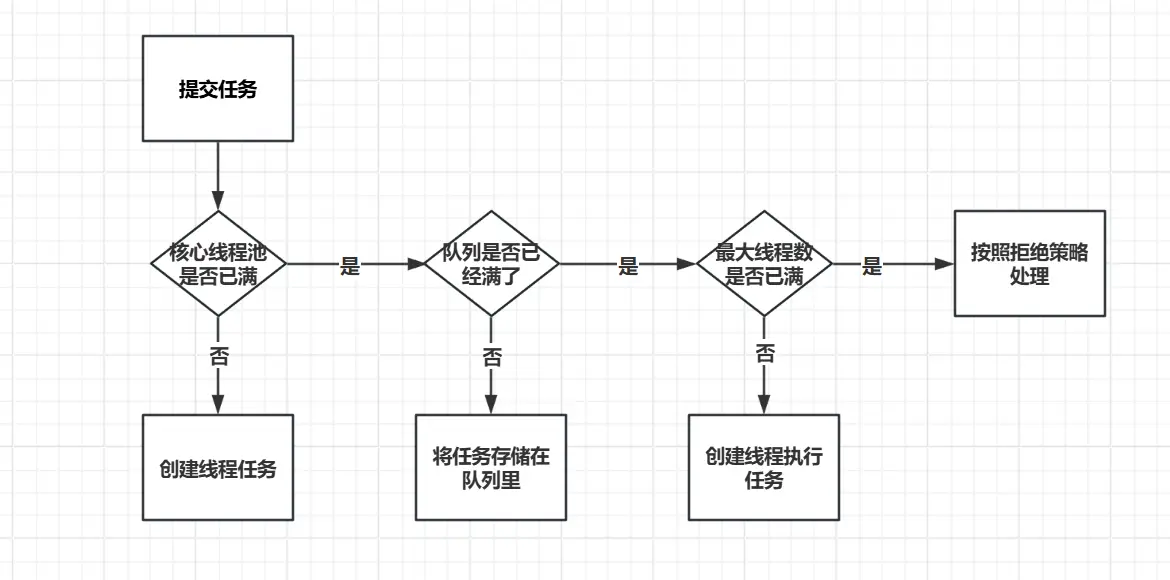
由上图可以看出,线程池有几个核心参数:
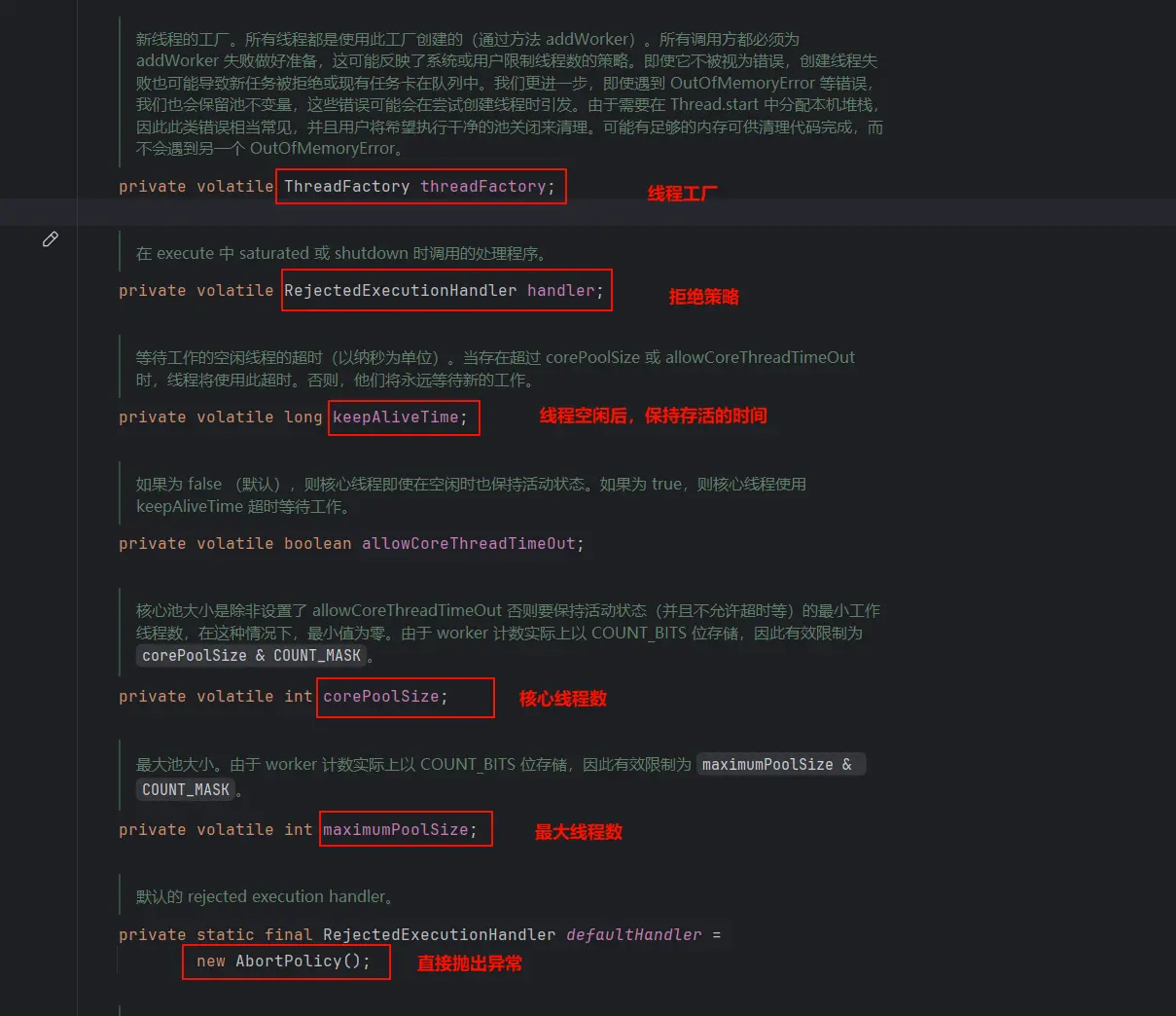
corePoolSize:核心线程数,当一个任务提交到线程池,但线程池线程小于核心线程数时,会创建一个线程执行BlockingQueue<Runnable>:任务队列,当线程池线程等于核心线程数时,不会立即创建新线程,而是把任务放到任务队列,等待执行maximumPoolSize:最大线程数,但任务队列满了,会创建新线程,直到线程数等于最大线程数RejectedExecutionHandler:线程数达到最大线程数时,此时该线程池以达到最大负载,新任务会触发拒绝策略keepAliveTime:线程池内空闲线程保持存活的时间
为什么线程池要有核心线程数和最大线程数的区分呢?
核心线程数和最大线程数中间有一个任务队列,用来暂时存放需要执行的任务,超过核心线程数的任务不一定要马上执行。如果仅仅依靠核心线程数,比如将核心线程数设置得很大,每次有新任务过来,都会创建新线程,会造成全局锁的获取,造成一个性能瓶颈
如何合理配置线程池
配置线程池需要考虑任务的特性,比如:
- CPU 密集型任务,任务瓶颈不在 CPU 上下文切换,应配置尽可能小的核心线程数,比如
CPU 核心数 + 1 - IO 密集型任务,应该配置尽可能多的核心线程数,比如
CPU 核心数 * 2 - 任务是否依赖其他系统资源,比如数据库连接(数据库同时支持 10 个连接,那么我的连接池核心线程数最大也应该设置为 10)
Executor 框架
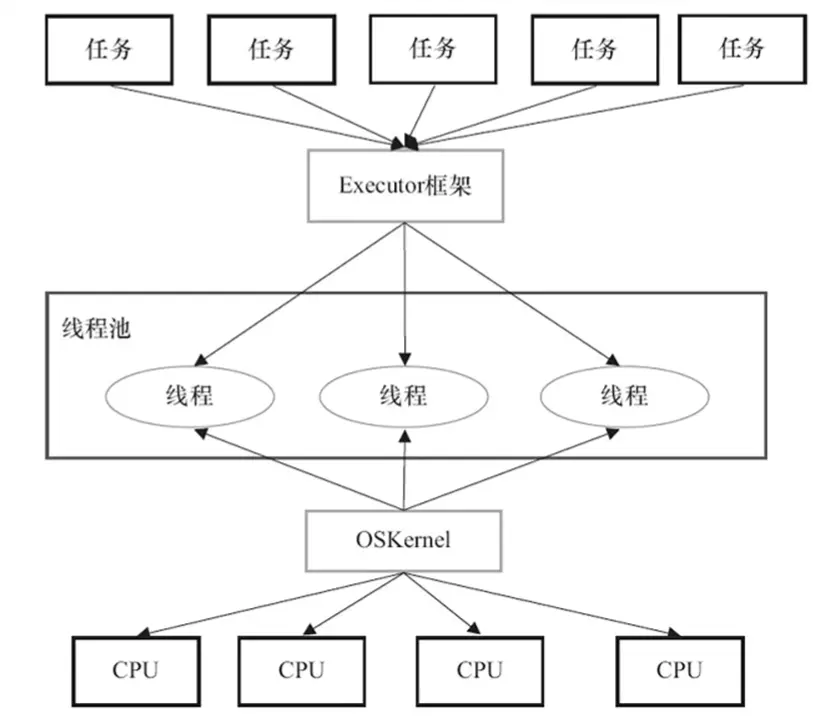
在 HotSpot JVM 的线程模型中,Java 线程被一对一映射到本地操作系统线程。
在上层, Java 多线程程序通常把应用分解为若干个任务,然后使用用户态的调度器 Executor 框架将这些任务映射为 Java 线程;操作系统内核再将 Java 线程映射到 CPU 底层执行。
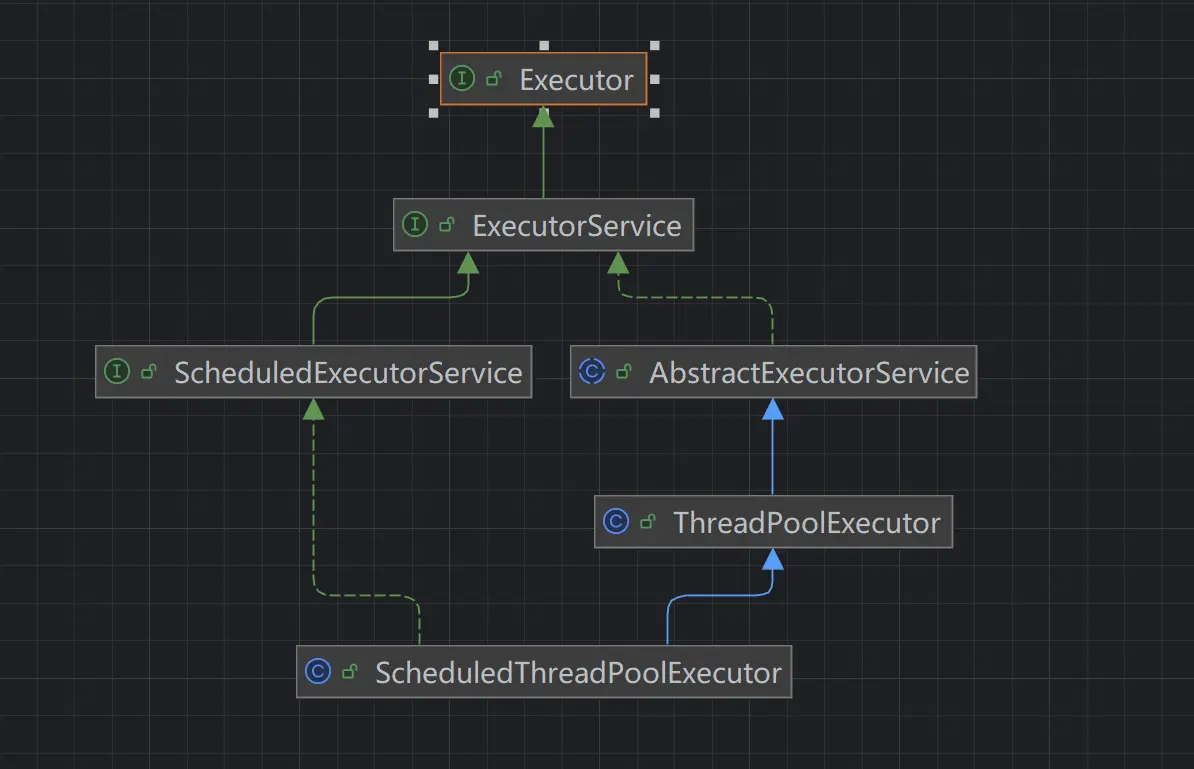
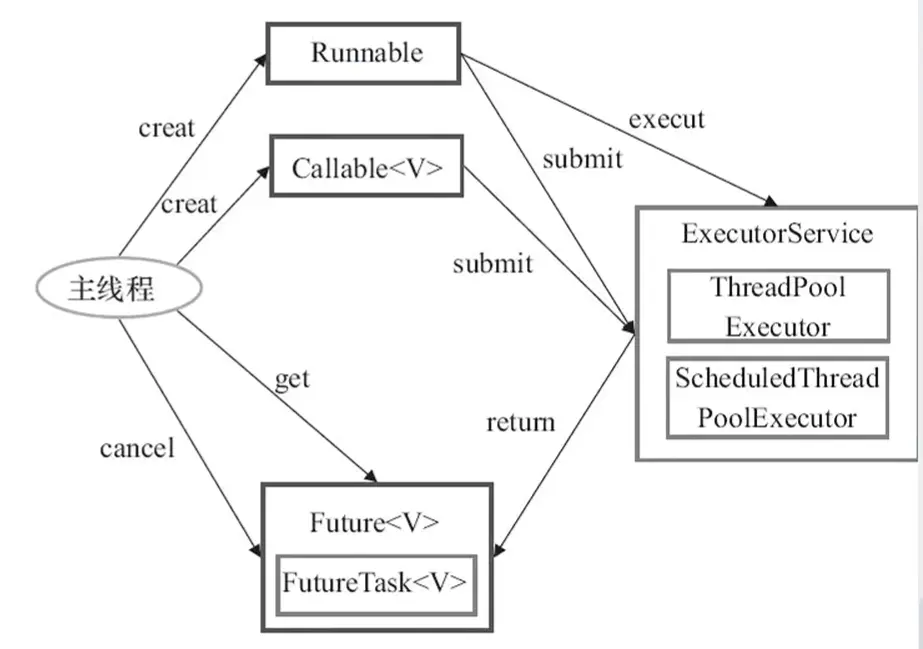
Executors 线程池工具类
Executors 线程池工具类,提供了 3 种类型的线程池,本质都是 ThreadPoolExecutor 线程池,只是参数不同,具体可以查看源码
newFixedThreadPool
从源码中即可看出 newFixedThreadPool 创建的是固定大小的线程池 (适用于 CPU 密集型任务,线程数固定)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor( nThreads, //核心线程数
nThreads, //最大线程数
0L, //空闲线程存活时间
TimeUnit.MILLISECONDS, //单位毫秒
new LinkedBlockingQueue<Runnable>()); //无界阻塞队列
}newSingleThreadExecutor
通过名字就可以看出创建的是一个单线程任务的线程池
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new AutoShutdownDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}newVirtualThreadPerTaskExecutor
JDK 21 新增,每个任务分配一个虚拟线程,无固定线程数限制,适合高并发 I/O 密集型任务(如 HTTP 服务)这也得益于 JDK21 引入的虚拟线程新特性,无需关注线程池参数调优,足够应对大部分场景,彻底改变了高并发编程模型 !
Fork/Join 框架
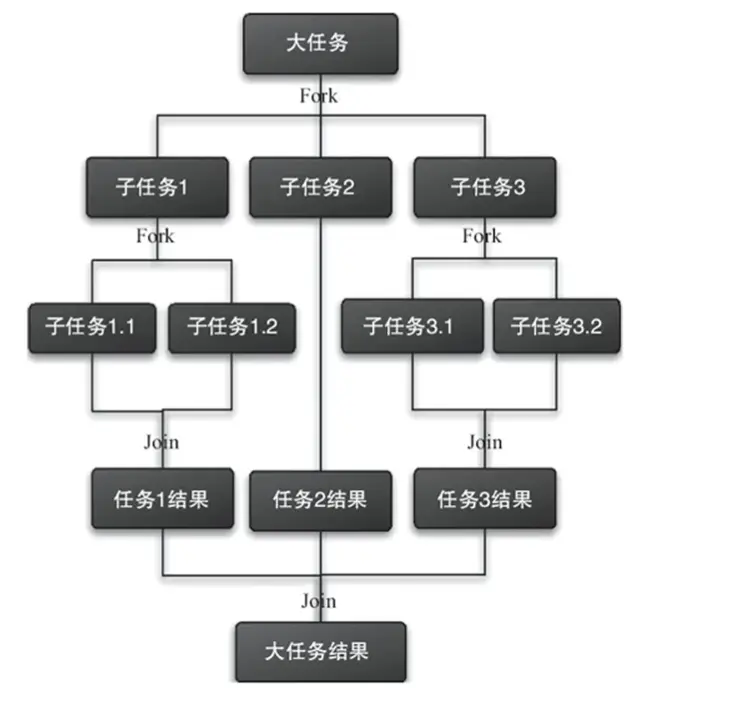
Fork/Join 框架是 Java 7 引入的一个并行执行任务的框架,把一个大任务分割为若干个小任务执行,最终汇总每个小任务的结果。我们要使用 Fork/Join 框架,必须先创建一个 ForkJoin 任务,可以通过继承 ForkJoinTask 子类来实现:
RecursiveAction:用于没有返回结果的任务RecursiveTask:用于有返回结果的任务
ForkJoin 计算 1 + 2 + 3 + ... + 100 案例
public class ForkJoinTest extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2; //最多几个数执行子任务
final int start; //从哪里相加 从1开始加
final int end; //加到哪里结束 加到100
public ForkJoinTest(int start, int end) {
this.start = start;
this.end = end;
}
// 拆分任务,获取结果
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
}else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
ForkJoinTest leftTask = new ForkJoinTest(start, middle);
ForkJoinTest rightTask = new ForkJoinTest(middle + 1, end);
// 分别执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完,并得到其结果
Integer leftResult = leftTask.join();
Integer rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) throws Exception {
try (ForkJoinPool forkJoinPool = new ForkJoinPool()) {
ForkJoinTest task = new ForkJoinTest(1, 100);
ForkJoinTask<Integer> result = forkJoinPool.submit(task);
System.out.println(result.get()); // 5050
}
}
}