ES 文本分析器
字数: 0 字 时长: 0 分钟
分词器
基本概念
分词器官方称之为文本分析器,是对文本进行分析处理的一种手段,根据预先定制的分词规则,把原始文本分割成若干更小粒度的词项,粒度大小取决于分词器规则。 注意:分词器不会对源数据造成任何影响,分词仅仅是对倒排索引的建立
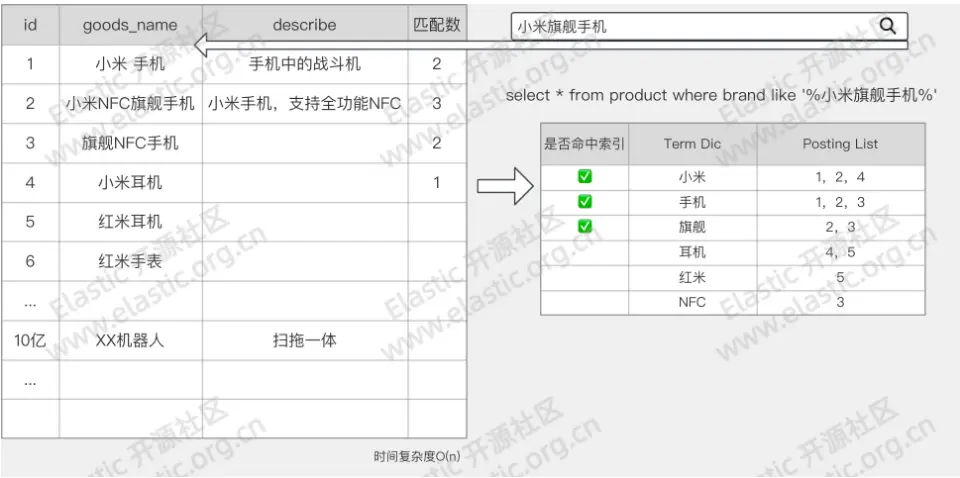
分词发生时期
分词器的处理过程发生在 Index Time 和 Search Time 两个阶段。
- Index Time:文档写入并创建倒排索引时期,其分词逻辑取决于映射参数
analyzer - Search Time:搜索发生时期,其分词仅对搜索词产生作用,其分词逻辑取决于搜索参数
search_analyzer
分词器组成
- 字符过滤器 (Char Filter):用于对原始文本进行字符处理
- 切词器 (Tokenizer):切割文本为一个个词项,默认切词器为
standard - 词项过滤器 (Token Filter):对切割后的单个词项处理,比如同义词替换,暂停词过滤等
基本用法
GET _analyze
{
"text":["What are you doing"],
"analyzer":"english"
}查看结果,可以发现 english 分词器将原文本分词为 what, you, do
{
"tokens": [
{
"token": "what",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "you",
"start_offset": 9,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "do",
"start_offset": 13,
"end_offset": 18,
"type": "<ALPHANUM>",
"position": 3
}
]
}字符过滤器 char filter
1. html 标签过滤器
html_strip 类型的字符过滤器将 HTML 标签进行过滤,比如 <p> </p> <a> </a> 等等
创建
my_char_filter为html_strip
PUT test_char_filter
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "html_strip"
}
}
}
}
}应用
standard分词器时指定字符过滤器为my_char_filter
GET test_char_filter/_analyze
{
"tokenizer": "standard",
"char_filter": ["my_char_filter"],
"text":["<p>I am so <a>happy</a></p>"]
}测试结果发现
<p></p><a></a>被过滤掉
{
"tokens": [
{
"token": "I",
"start_offset": 3,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "am",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "so",
"start_offset": 8,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "happy",
"start_offset": 14,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 3
}
]
}2. 字符映射过滤器
字符映射过滤器(mapping)可以将一些字符映射为 *
PUT test_mapping_filter
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter":{
"type":"mapping",
"mappings":[
"滚 => *",
"垃 => *",
"圾 => *"
]
}
}
}
}
}
GET test_mapping_filter/_analyze
{
"tokenizer":"standard",
"char_filter":["my_char_filter"],
"text":"你就是个垃圾,滚!"
}
// 垃 圾 滚 被映射为了 * ,然后 * 被视为无意义词停用,因此分词结果如下:
{
"tokens": [
{
"token": "你",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "就",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "是",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "个",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}3. 正则替换过滤器
正则替换过滤器(pattern_replace)可以使用正则表达式对部分字符进行替换:
PUT text_pattern_replace_filter
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type":"pattern_replace",
"pattern": """(\d{3})\d{4}(\d{4})""",
"replacement":"$1****$2"
}
}
}
}
}
GET text_pattern_replace_filter/_analyze
{
"char_filter":["my_char_filter"],
"text": "您的手机号是 18868686688"
}切词器 Tokenizer
Tokenizer 是分词器的核心组成之一,它将原始文本切割为若干个词项,比如 I am a good man 切割为 I, am, a, good, man。拆分之后的每一个部分称为一个 Term 词项。
// 创建 `my_tokenizer` ,发现结果将通过 `,` `.` `!` `?` 进行拆分
PUT test_tokennizer
{
"settings": {
"analysis": {
"tokenizer": {
"my_tokenizer":{
"type":"pattern",
"pattern":[",.!?"]
}
}
}
}
}
GET test_tokennizer/_analyze
{
"tokenizer":"my_tokenizer",
"text":"我,爱!甜甜"
}
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "word",
"position": 0
},
{
"token": "爱",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "甜甜",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 2
}
]
}词项过滤器 Filter
词项过滤器用来处理切词完成之后的词项,例如大小写转换,删除停用词或同义词处理等
大小写转换
GET _analyze
{
"filter":["lowercase"],
"text": "WE ARE FAMILY!"
}
// 查看结果,单词都被转换为小写
"tokens": [
{
"token": "we are family!",
"start_offset": 0,
"end_offset": 14,
"type": "word",
"position": 0
}
]
}停用词处理
处理停用词,停用词就是那些对检索无意义的词,可以将其忽略。比如将网址中的 www 忽略掉
PUT test_token_filter_stop
{
"settings": {
"analysis": {
"filter": {
"my_filter":{
"type": "stop",
"stopwords":["www"],
//忽略大小写
"ignore_case":true
}
}
}
}
}分词后发现, www 与 WWW 都已经被停用
GET test_token_filter_stop/_analyze
{
"tokenizer":"standard",
"filter":["my_filter"],
"text": ["What www WWW are you doing"]
}
{
"tokens": [
{
"token": "What",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "are",
"start_offset": 13,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "you",
"start_offset": 17,
"end_offset": 20,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "doing",
"start_offset": 21,
"end_offset": 26,
"type": "<ALPHANUM>",
"position": 5
}
]
}同义词
同义词就是当用户搜索 flim 时,如果结果当中有 movie 也可以被检索到
a,b,c => d这种方式 a b c 都会被 d 替代a,b,c,d这种方式 a b c d 是等价的
PUT test_token_filter_synonym
{
"settings": {
"analysis": {
"filter": {
"my_synonym":{
"type":"synonym",
"synonyms":[
"a,b,c => d"
]
}
}
}
}
}验证结果,发现我们通过 a 检索得到的结果是 d
GET test_token_filter_synonym/_analyze
{
"tokenizer": "standard",
"filter":["my_synonym"],
"text":["a"]
}
{
"tokens": [
{
"token": "d",
"start_offset": 0,
"end_offset": 1,
"type": "SYNONYM",
"position": 0
}
]
}内置分词器
- standard : 默认分词器,对中文支持不理想,会逐字拆分
GET /_analyze
{
"analyzer":"standard",
"text":["我是甜甜"]
}
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "甜",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "甜",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}- pattern : 以正则匹配分隔符,把文本拆分成若干词项
- simple : 除了英文单词和字母,其他统统过滤掉
- whitespace : 以空白符分割
- keyword : 不做任何分词操作
- stop : 增加了对停用词的支持
- language analyzer : 支持全球三十多种语言,对中文支持不好
自定义分词器
如果 ES 内置分词器无法满足我们需求,可以自定义分词器或者使用第三方分词器
8PUT test_analyzer
{
"settings": {
"analysis": {
//字符过滤器 ,过滤 html 标签
"char_filter": {
"my_char_filter": {
"type": "html_strip"
}
},
// 切词器 通过 , . ! ? 符号进行切词
"tokenizer": {
"my_tokenizer":{
"type": "pattern",
"pattern":[",.!?"]
}
},
// 词项过滤器 , 无视大小写,将 www 作为停用词
"filter": {
"my_filter":{
"type":"stop",
"stopwords":["www"],
"ignore_case":true
}
},
// 自定义分词器,应用上面的字符过滤器、切词器、词项过滤器
"analyzer": {
"my_analyzer":{
"type":"custom",//可缺省
"tokenizer":"my_tokenizer", //切词器只能有一个
"char_filter":["my_char_filter"],
"filter":["my_filter"]
}
}
}
}
}验证结果
GET test_analyzer/_analyze
{
"analyzer": "my_analyzer",
"text": ["asdad,www,elastic!org?cn elasticsearch"]
}
{
"tokens": [
{
"token": "asdad",
"start_offset": 0,
"end_offset": 5,
"type": "word",
"position": 0
},
{
"token": "elastic",
"start_offset": 10,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "org",
"start_offset": 18,
"end_offset": 21,
"type": "word",
"position": 3
},
{
"token": "cn elasticsearch",
"start_offset": 22,
"end_offset": 38,
"type": "word",
"position": 4
}
]
}文档归一化器 normalizers
在 ES 中, normalizers 是专门用于处理关键字 keyword 字段的轻量级分析链。它的主要目的是对文本进行标准化处理,确保不同的写法或格式能够统一表示,从而不影响搜索结果。归一化器只包含字符过滤器和标记过滤器,没有切词器
配置一个归一化器,对
user_name字段进行小写转换
PUT /normalizer_index
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": {
"char_filter": [],
"filter": ["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"user_name": {
"type": "keyword",
"normalizer": "my_normalizer"
}
}
}
}然后发现,使用 tom 或 Tom 或 TOM 都能检索到这一条数据
PUT normalizer_index/_doc/1
{
"user_name":"tom"
}
GET normalizer_index/_search
{
"query": {
"term": {
"user_name": {
"value": "Tom"
}
}
}
}