核心概念
字数: 0 字 时长: 0 分钟
1、节点 Node
一个 Node 就是一个 ElasticSearch 实例,一个服务器可以部署多个 Node。
2、角色 Roles
常见角色
- 主节点 (active master) : 一个集群中只能有一个,主要作用是对集群的管理,配置了
master的节点不一定是主节点,更准确的说应该叫做候选节点,只有选举胜出的节点才是主节点 - 候选节点(master-eligible): 当主节点发生故障时,具有选举权和被选举权
- 数据节点(data node): 主要工作节点
- 预处理节点(ingest node): 预处理节点有点类似于
logstash的消息管道,也叫ingest pipeline,常用于一些数据写入之前的预处理操作
角色配置
准确的说,节点角色的配置方式。注意如果 node.roles 为缺省配置,那么默认拥有所有角色。ES 节点角色深层解读博文 : ES节点角色深层解读,及高可用集群架构角色设计
node.roles=[master,xxx,xxx]3、索引 Index
在 ES 中,索引在不同的特定条件下可以表示三种不同的意思:
- 表示源文件数据: 类比数据库中的
table(7.X 版本之后) - 表示索引文件: 以加速查询检索为目的而设计和创建的数据文件,通常承载于某些特定的数据结构,如哈希、FST等。通常所说的 倒排索引 就是这个表述,索引文件和源数据是完全独立的。
- 表示创建数据的动作: 索引一条文档的含义即向索引中添加一条文档
4、类型
在最初的设计中,索引 类比 数据库,类型 类比 表,但数据库中 User 表中的 name 和 Address 表中的 name 是相互独立的, 但在 ES 中 User 类型和 Address 类型的 name 在底层由相同的 Lucene 字段支持;而且在同一索引中存储具有很少或没有公共字段的不同实体会导致数据稀疏,影响 Lucene 有效压缩文档的能力。
因此类型 Type 的概念在 ES 7.X 版本中官方就已经废弃,官方使用 _doc 代替。索引类比数据库中的表,为每个文档类型单独设置一个索引。
5、文档 Document
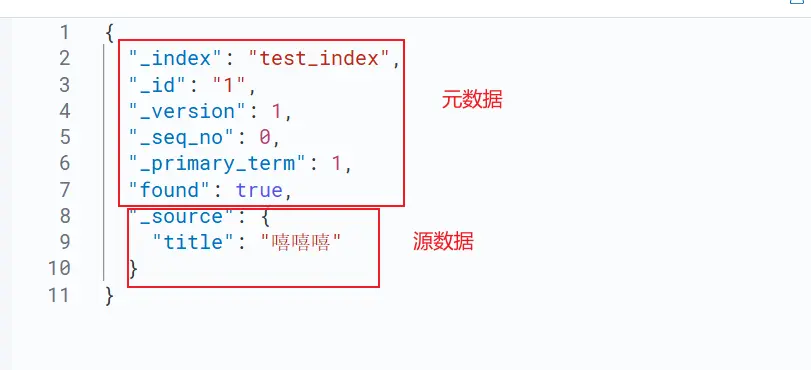
ES 中的每个 document 就代表一条数据,由 元数据 和 源数据 两部分组成:
元数据
- _index : 索引名称
- _id : 文档 id
- _version : 版本号
- _seq_no : 索引级别的版本号,索引中的所有文档共享一个 _seq_no
- _primary_term: 当主分片发生重新分配时,该值会递增1。主要作用是用来恢复数据时处理当多个文档的 _seq_no 一样时的冲突,避免主分片数据写入被覆盖
源数据
指业务数据,最终写入的用户数据
6、集群 Cluster
ES 是天生分布式的,ES 集群是自动发现的,无需任何网络配置, ES 将绑定到可用的环回地址并扫描本地端口 9300 到 9305 连接同一服务器上运行的其他节点,自动形成集群。
核心配置
network.host: 提供服务的 IP 地址,一般为本节点所在服务器的内网地址,此配置会导致节点由开发模式转为生产模式,触发引导检查network.publish_host: 提供服务的公网 IP 地址http.port: 服务端口号,默认 9200 ,通常范围 9200 ~ 9300transport.port: 节点通信端口,默认 9300, 通常范围 9300 ~ 9399discovery_seed_hosts: 集群中其他候选节点的列表cluster.initial_master_nodes: 指定集群初次选举中用到的候选节点,称为集群引导,只在第一次形成集群时需要
集群的健康值检查
- 绿色:所有分片都可用
- 黄色:至少有一个副本不可用,但是所有主分片都可用,集群能提供完整的读写服务,但是可用性较低。
- 红色:至少有一个主分片不可用,数据不完整。此时集群无法提供完整的读写服务。集群不可用。
// 方法一 : _cat API
GET _cat/health
//方法二 : _cluster API
GET _cluster/health集群的故障诊断
常用 API
_cat/indices查看集群中所有索引_cat/health?v=true查看健康状态_cat/nodeattrs查看节点属性_cat/nodes?v查看集群中的节点_cat/shards查看集群中所有分片的分配情况_cluster/allocation/explain可用于诊断分片未分配原因_cluster/health/检查集群状态
索引未分配原因
ALLOCATION_FAILED: 由于分片分配失败而未分配CLUSTER_RECOVERED: 由于完整群集恢复而未分配.DANGLING_INDEX_IMPORTED: 由于导入悬空索引而未分配.EXISTING_INDEX_RESTORED: 由于还原到闭合索引而未分配.INDEX_CREATED: 由于API创建索引而未分配.INDEX_REOPENED: 由于打开闭合索引而未分配.NEW_INDEX_RESTORED: 由于还原到新索引而未分配.NODE_LEFT: 由于承载它的节点离开集群而取消分配.REALLOCATED_REPLICA: 确定更好的副本位置并取消现有副本分配.REINITIALIZED: 当碎片从“开始”移回“初始化”时.REPLICA_ADDED: 由于显式添加了复制副本而未分配.REROUTE_CANCELLED: 由于显式取消重新路由命令而取消分配.
分片
分片可以理解为索引的碎片,并且所有的碎片都是可以无限复制的。分片的存在主要是为了高可用性以及提高吞吐量和并发响应的能力。
- 一个索引包含一个或多个分片,在
7.0之后默认一个主分片、一个副本分片。主分片的数量一旦确定就不可修改,副本分片可以在创建之后修改数量 - 每个分片都是一个
lucene实例,有完整的创建索引和处理请求的能力 - ES 会自动在
nodes上做分片均衡,当节点上分片数量达到一定阈值时,会自动将分片迁移到其他节点上 - 一个
doc不可能同时存在于多个主分片中,但可以同时存在于多个副本分片中 - 主分片和其副本分片不能同时存在于同一节点上
- 完全相同的副本不能同时存在于同一节点上