MySQL 索引
字数: 0 字 时长: 0 分钟
索引是帮助 MySQL 高效获取数据的数据结构。没有索引的话查找数据需要全表扫描,只能一一遍历直到找到目标数据;而有索引,则可以减少数据库的 IO 成本,更快的查找到数据。
索引不是无副作用的完美方案,因为索引本身也会占用一定的空间,增删改数据时需要维护索引的变动也需要开销,降低了更新性能。因此使用索引时,需要综合考虑索引的优缺点,不能无脑地为所有数据建索引。
索引数据结构
1. 哈希表
哈希表是一种非常高效的数据结构,查询算法复杂度为 O(1),JDK 中的 HashMap 就是采用这个数据结构,但有一个致命缺点就是 数据分布无序,无法支持范围查询。
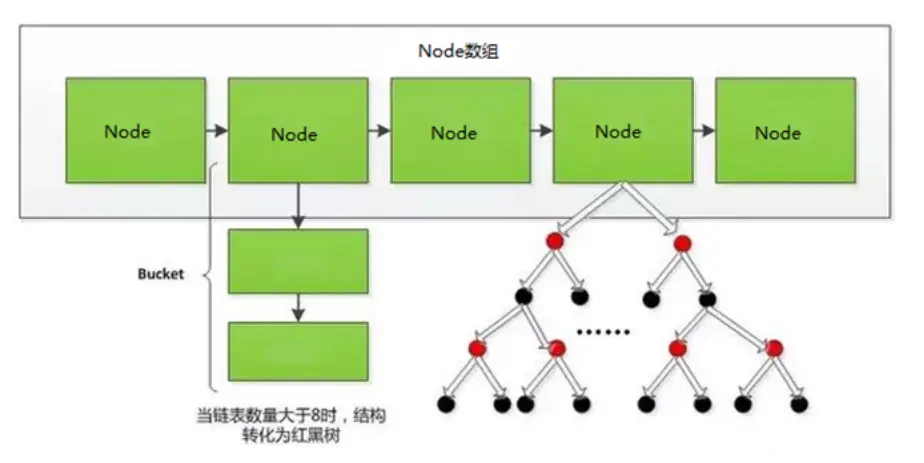
二叉搜索树
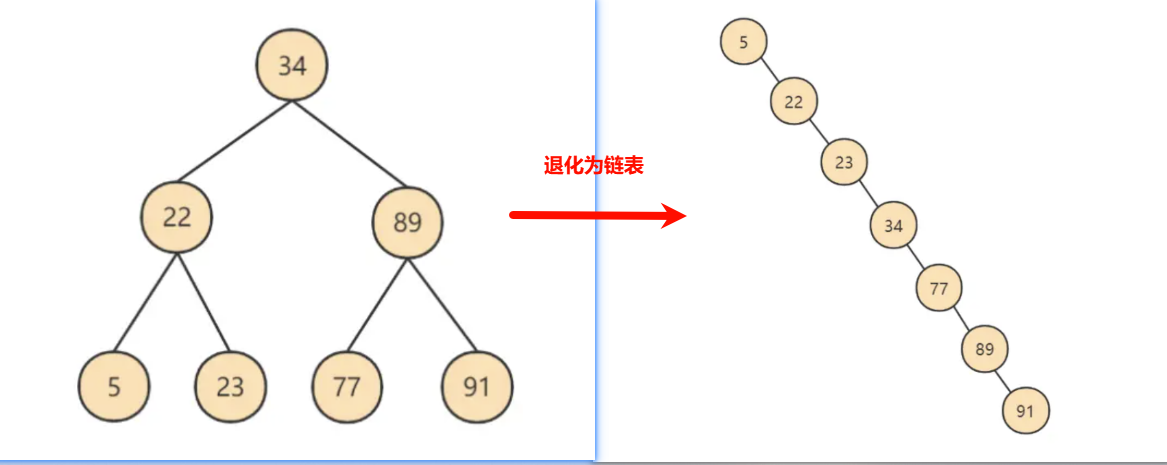
二叉搜索树是有序的,虽然效率不如哈希表高,但解决了无序问题。不过二叉树又引入了新的缺点,就是极端情况下会退化为链表,复杂度变为 O(n)
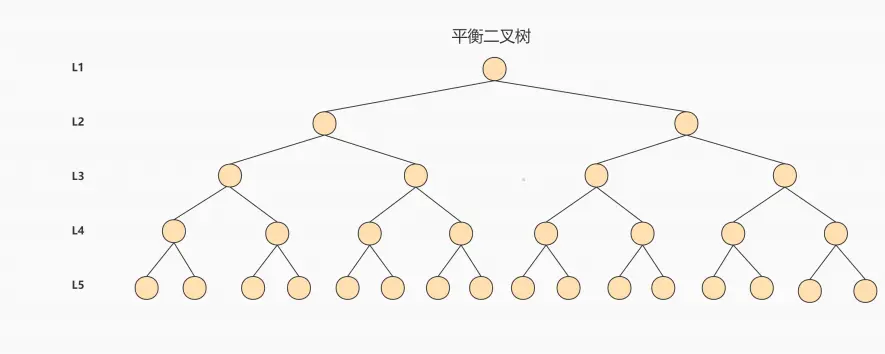
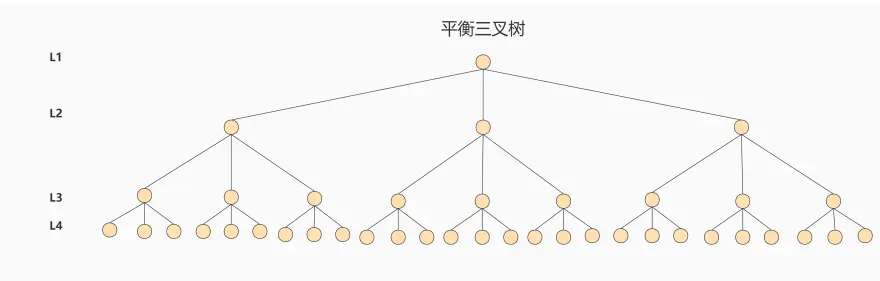
AVL树/红黑树
AVL树和红黑树都是平衡二叉搜索树,区别是 AVL 是严格平衡(查询效率更高,更新效率更低),红黑树是近似平衡(平衡了查询效率与更新效率)。这两者都解决了二叉搜索树退化为链表的问题,优化了查询效率,不过还有不足:数据越多树的高度越深查询复杂度越高。
B 树
如果把二叉树变为 N 叉树呢,也就是 B 树,那么树的深度就会大幅降低
B + 树
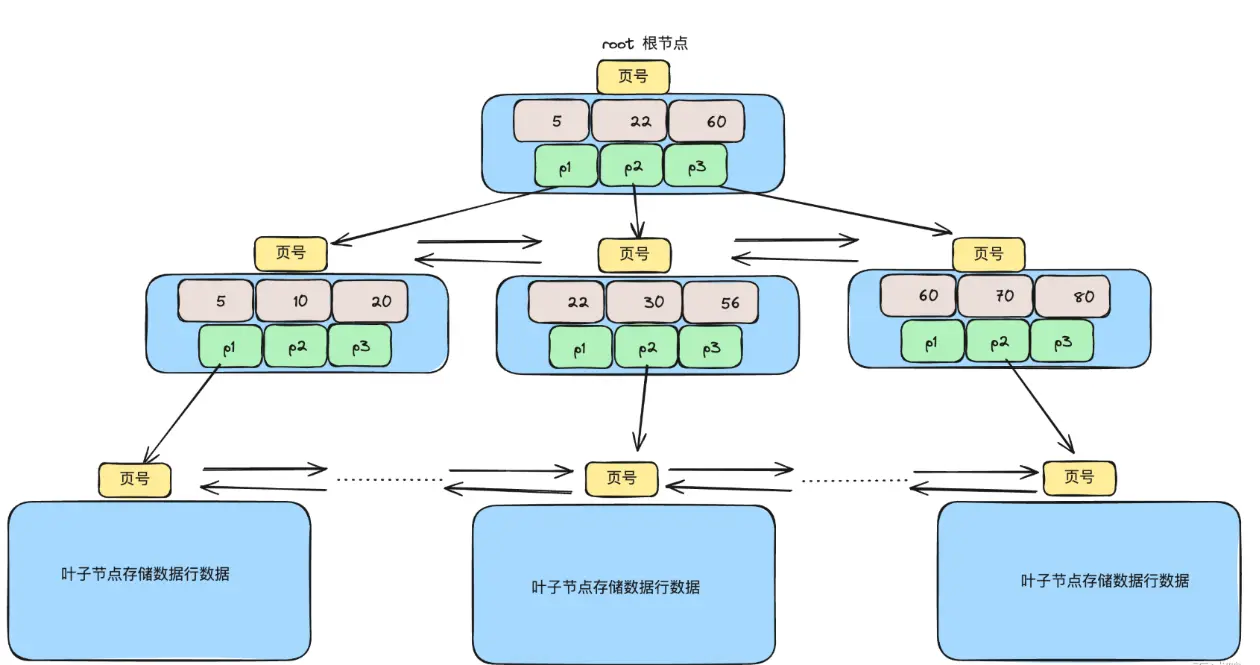
貌似 B 树已经很优秀了,不过 MySQL 索引的数据结构是 B+ 树,有以下特点:
- 非叶子节点只存键和指针,不存数据(相对 B树,单页能存更多索引,树更矮)
- 叶子节点之间双向链表连接(相对 B树,连续范围扫描只需遍历列表,而 B树 需要多次跨层遍历)
- 叶子节点按键值有序排列(天然支持范围查询和排序)
- 多叉平衡树结构(单节点能存多个键值,相对红黑树极大压缩树高)
在 InnoDB 中,B+ 树的每个节点通常对应一个页,也就是 16KB,假设每个数据记录的主键和数据大小为 1KB (实际一般比这个小),每个指针 6 字节,键为 bigint 8 字节。
- 叶子节点:每个叶子节点可以存储
(16KB / 1KB)16 条数据 - 中间层:每个节点可以存储 1170 个叶子节点
- 根节点:可以存储 1170 个中间节点
所以一棵三层的 B+ 树大概能存 1170 * 1170 * 16 大约 2000 万条记录
索引的分类
从 功能逻辑 上说,索引主要有 4 种:
- 普通索引(二级索引、辅助索引):不需要限制条件,可以创建在任意字段上
- 唯一索引:只能创建在满足唯一性的字段上
- 主键索引:主键自动带有主键索引,具有唯一性和非空性
- 全文索引:用于全文检索,实际上应用有限,相关功能一般用专业搜索引擎,如 ElasticSearch
从 基于 InnoDB B+ 树结构 来分,索引分为聚簇索引和非聚簇索引
聚簇索引
叶子节点存储有完整的数据,每个表只能有一个聚簇索引,通常是主键索引(如果没有指定主键,会自动隐式地创建一个),适合范围查询和排序
非聚簇索引
非主键索引都是非聚簇索引,叶子节点存储的是数据行的主键和索引列,需要通过此主键回到聚簇索引中查找对应的完整数据,这个过程称为回表。如果只需要查找索引列,则不需要回表,这种情况也称为索引覆盖。
索引下推
索引下推是一种减少回表查询,提高查询效率的技术。它允许 MySQL 在使用索引查找数据时,将部分查询条件下推到存储引擎层过滤, 从而减少需要从表中读取的数据行,减少了 IO(本该 Server 层操作,交由存储引擎层,因此叫做 “下推” )
索引的设计原则
索引也是有时间和空间成本的,比如新增一个普通索引,就要新增一颗 B+ 树占用存储空间;每次更新数据都需要去维护更新索引,这是时间成本。而且索引不一定有效,比如很多场景下索引会失效:
- 使用了联合索引却不符合最左前缀
比如对 user 表建立了一个由 name + age 实现的 name_age_index 联合索引,但是查询 SQL 为 select * from user where age = 10 and name = '张三',此时不符合最左前缀无法匹配索引
- 索引中使用了运算或函数
比如 select * from user where id + 3 = 8,这会导致全表扫描计算 id 的值再进行比较,导致索引失效。同理如果使用不正确的字段类型,比如 age 本应该是 int 却写为了 varchar,是会触发隐式函数转换也导致索引失效
like的随意使用
比如 select * from user where name like '%张三%',因为索引从左到右进行排序查找,这里占位符直接放最左边可能导致全表扫描
or的随意使用
比如 user 表当前只有 name 索引,但 SQL 为 select * from user where name = '张三' or age = 10,因为 age 没有索引,导致全表扫描
- 表中两个不同字段进行比较
比如 select * from user where id > age
- 使用了
order by,后面跟的不是主键或覆盖索引会导致索引失效
不适合建立索引的情况
以上介绍了索引失效的情况,还有一些情况索引尽管成功了,但效率可能还不如不建索引:
- 对于数据量很小的表:创建索引不会显著提高性能,还增加了管理的复杂性
- 频繁更新的表:维护索引的开销太大
- 执行大量的
select *:此时二级索引可能不会显著提升性能,因为需要大量的回表,开销大甚至可能导致全表扫描 - 重复度高的列:比如性别字段,索引效果不明显
- 低频查询的列:索引是通过降低更新性能来提高查询性能的,如果查询需求低,则不要建立索引
- 长文本字段:
TEXT这类非常长的字段甚至不应该放到 MySQL (每个页存放的行数很少,扫描查询需要大量 IO 操作),可以使用 ES 来实现查询
SQL 调优
通过以上对数据库索引的深入理解,我们就可以得出一些 SQL 调优方法了:
- 合理设计索引,利用联合索引进行索引覆盖,这样可以避免回表
- 避免
select *,只查询必要的字段 - 避免在 SQL 中进行函数计算等操作,使得索引失效
- 避免使用
%LIKE导致全表扫描 - 注意联合索引需满足最左匹配原则
- 不要对无索引字段进行排序操作
- 连表查询需要注意不同字段的字符集是否一致,否则会触发隐式的函数转换,导致索引失效
除了 SQL 层面的优化,还可以利用缓存来优化查询效率;或者通过业务来优化一些不必要的字段,减少多表查询
explain 性能分析
我们只需在要执行的查询语句之前添加 explain 关键字,就可以查看查询计划(比如是走索引还是全表扫描)。EXPLAIN 语句输出的各个列的作用如下:
| 列名 | 含义 |
|---|---|
| id | 每个 select 关键字都对应一个 唯一的id |
| select_type | SELECT 关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际使用的索引 |
| key_len | 索引长度 |
| ref | 索引列的列值 |
| rows | 扫描的行数 |
| filtered | 扫描的行数 / 总行数 |
| Extra | 额外的信息,如使用索引、使用临时表、使用子查询等 |
测试数据准备
# 建表 s1
CREATE TABLE s1 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
# 建表 s2
CREATE TABLE s2 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
# 创建函数如果报错,需要开启允许创建函数配置
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
# 创建函数
DELIMITER //
CREATE FUNCTION rand_string1(n INT)
RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
# 创建往 s1 表插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_s1 (IN min_num INT (10),IN max_num INT (10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO s1 VALUES(
(min_num + i),
rand_string1(6),
(min_num + 30 * i + 5),
rand_string1(6),
rand_string1(10),
rand_string1(5),
rand_string1(10),
rand_string1(10));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
# 创建往 s2 表插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_s2 (IN min_num INT (10),IN max_num INT (10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO s2 VALUES(
(min_num + i),
rand_string1(6),
(min_num + 30 * i + 5),
rand_string1(6),
rand_string1(10),
rand_string1(5),
rand_string1(10),
rand_string1(10));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
# 调用存储过程,为 s1 表添加 1 万条记录
CALL insert_s1(10001,10000);
# 调用存储过程,为 s2 表添加 1 万条记录
CALL insert_s2(10001,10000);一般主要关注 EXPLAIN 结果的 type 、key 、rows
type访问类型:性能由高到低,阿里巴巴手册要求SQL性能优化时达到ref级别,最低达到range级别
| 值 | 含义 |
|---|---|
const | 常数级访问,当根据主键或唯一索引与常数进行等值匹配时 |
eq_ref | 连接查询时,被驱动表通过主键或唯一索引等值匹配时 |
ref | 通过普通索引与常量进行等值匹配时 |
ref_or_null | 普通索引与常量进行等值匹配时,该值可能为 null 时 |
range | 使用索引进行范围匹配时 |
index | 使用索引进行全表扫描时(查询结果字段就是索引) |
ALL | 全表扫描时 |
key: 表示实际用到的索引,如果这个值是NULL,则表示查询没有使用索引rows: 表示查询扫描的行数