Broker
字数: 0 字 时长: 0 分钟
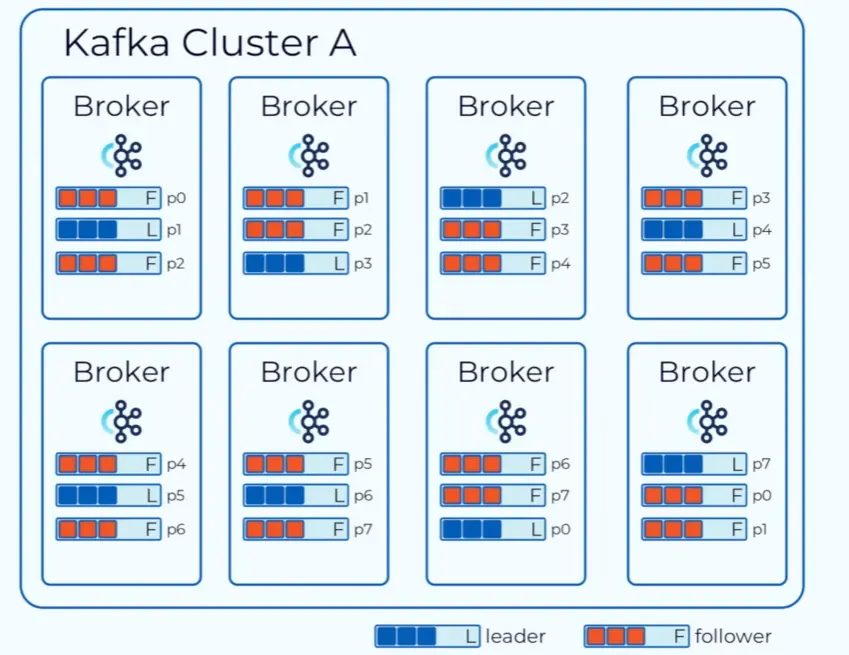
Kafka 集群
Kafka 集群中有多个 Broker 节点,每个 Broker 分布在不同的机器上;为了提供吞吐量,每个 Topic 会有多个分区,每个分区还会有多个副本,这些分区副本均匀的散落在每个 Broker 上,每个分区中有一个为 Leader,其他分区副本为 Follower。
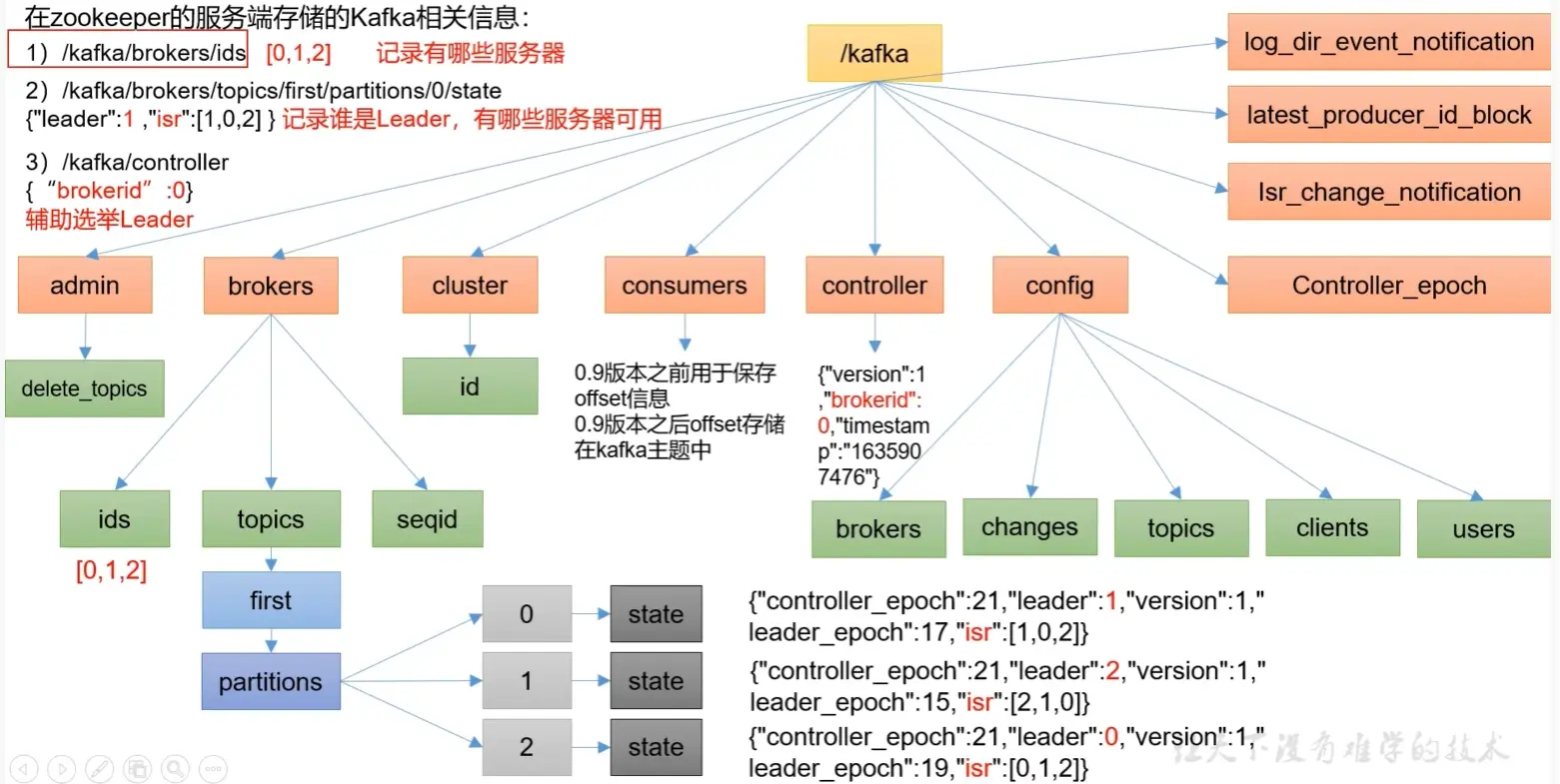
Zookeeper 充当注册中心的作用,用以存储 Kafka 集群的元数据信息。
Broker 工作流程
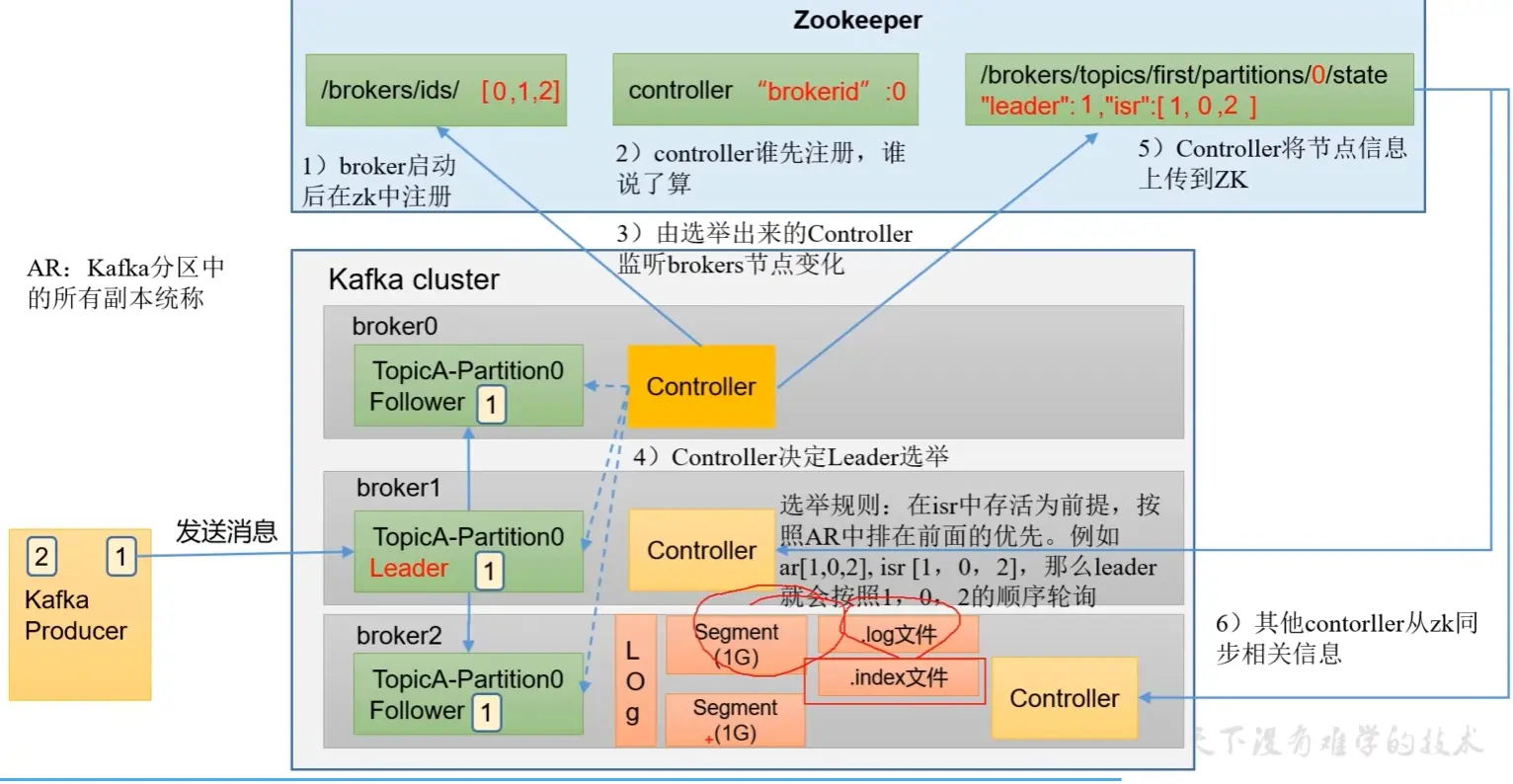
- Broker 启动后在 zk 中注册
- 每个 Broker 节点都有一个 Controller,哪个 Broker 的 Controller 先注册到 ZK 中,谁就决定 Leader 选举。
- Controller 监听 Broker 节点的变化,以在 ISR 中存活为前提按照 AR 中排在前面的顺序进行选举 Leader
- Controller 将选中的 Leader 节点注册到 ZK 中,其他 Broker 节点的 Controller 也会从 ZK 中同步 Leader 节点信息(Leader 挂了随时准备上位)。
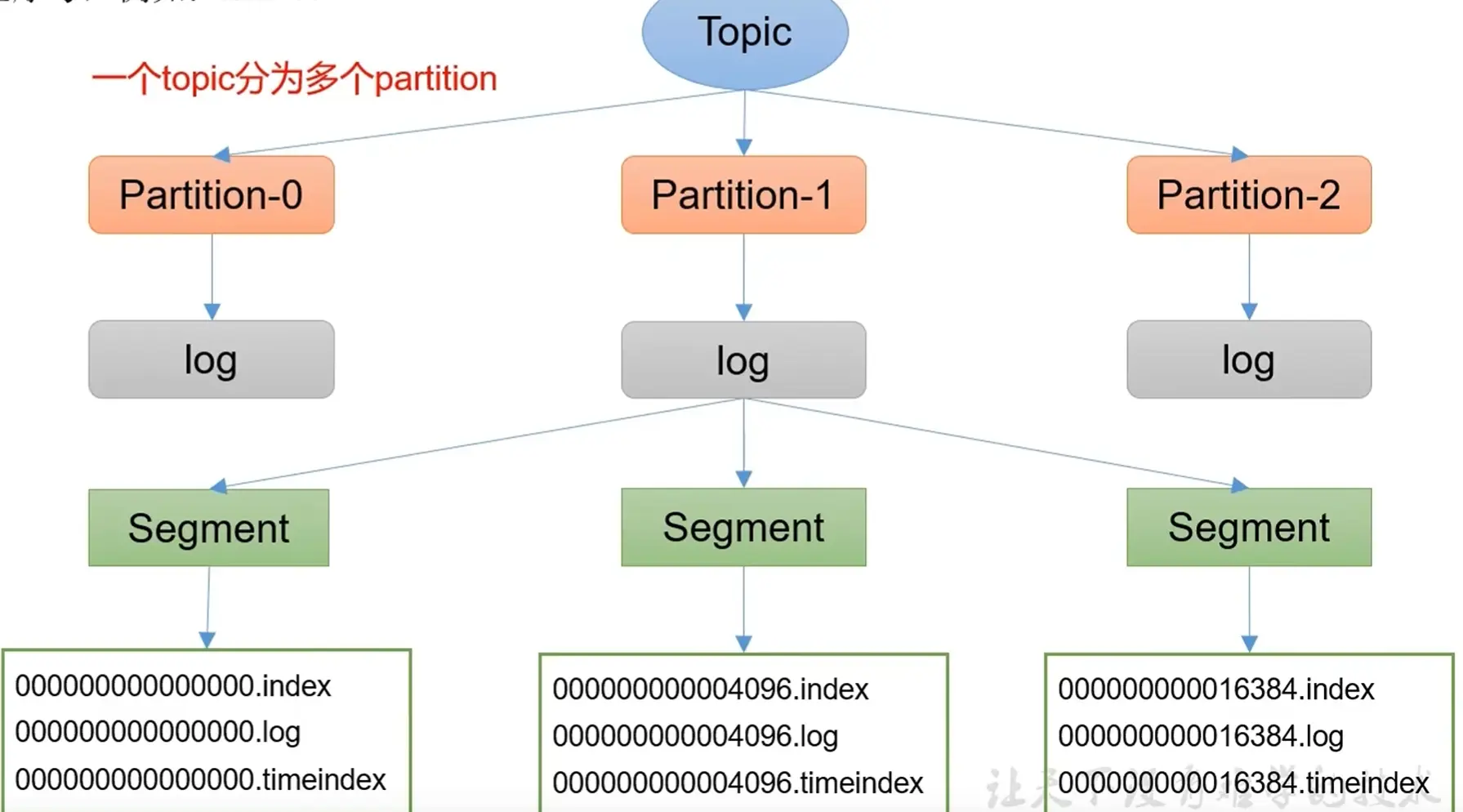
kafka 文件存储机制
Topic 是逻辑上的概率,Partition 是物理上的分区,每个分区对应一个 log 文件,该 log 文件存储 Producer 生产的数据。 Producer 生产的数据会不断追加到该 log 文件的末端,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片 和 索引 机制。
一个 partition 分为多个 segment ,每个 segment 包括 .index、.log和.timeindex 文件,这些文件位于同一个文件夹下,命名为 topic + 分区号
日志清除策略
Kafka 中的默认日志保存时间是 7 天,可通过以下参数修改:
log.retention.hours:最低优先级小时,默认 7 天log.retention.minutes:分钟log.retention.ms:最高优先级毫秒log.retention.check.interval.ms:超时检查周期,默认 5 分钟
删除:可以使用 log.cleanup.policy=delete 开启过期日志删除策略,默认基于时间过期进行删除,也可以基于文件大小进行删除。
压缩:使用 log.cleanup.policy=compact 开启过期日志压缩策略,即对于相同 key 的不同 value 值,只保存最后一个版本。
Kafka 为什么能高效读写?
- Kafka 本身是分布式集群,采用分区技术,并行度高。
- 读数据采用稀疏索引,每个 segment 默认存
1G数据,使用.index可以快速定位到要消费的数据。 - 写数据采用顺序写磁盘,数据是不断追加到 log 文件末端的,省去了大量磁头寻址时间。
- 页缓存 和 零拷贝