Consumer 消费者
字数: 0 字 时长: 0 分钟
推 / 拉模式
消息队列消费模式有两种:
- 推模式:Broker 将消息推给消费者,好处是实时性好,不过难以适应消费者消费速度
- 拉模式:消费者主动从 Broker 拉取数据,Kafka 采用拉模式,缺点是如果 Broker 没有数据会空轮询
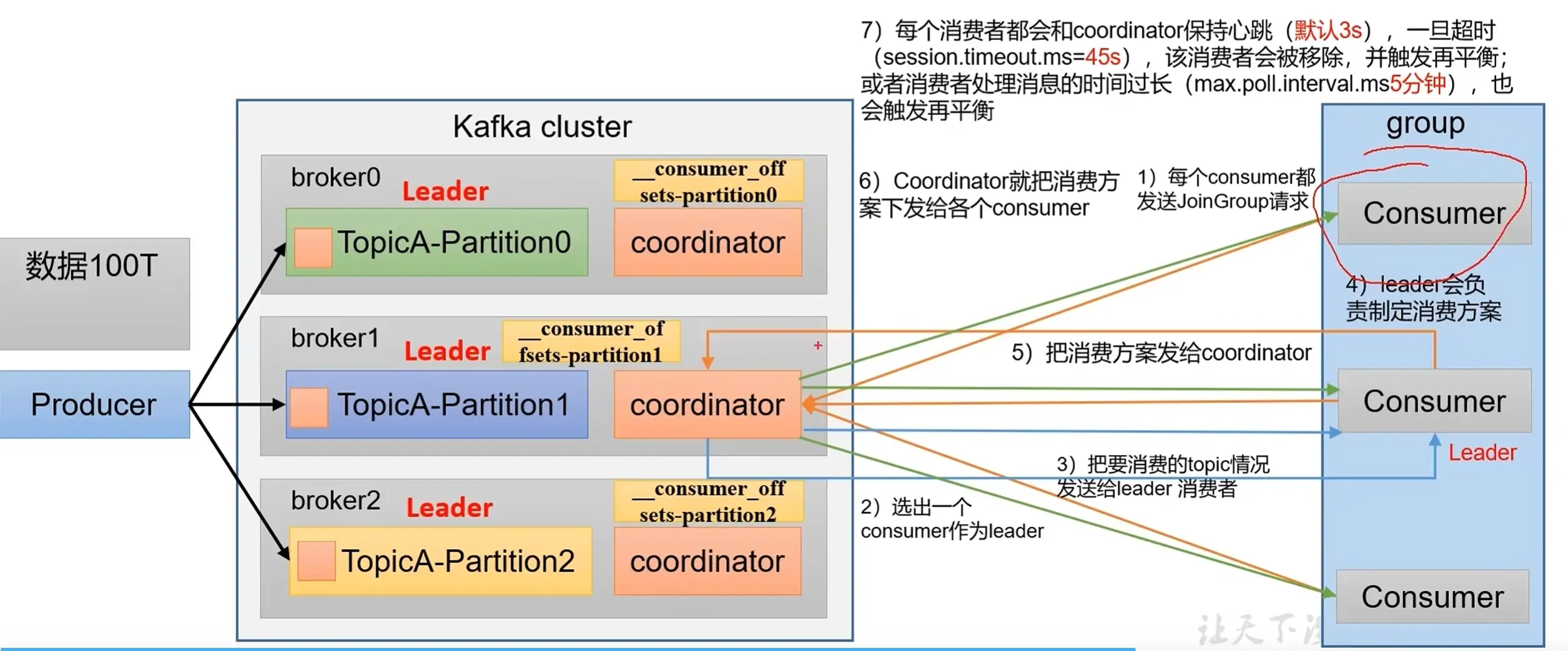
消费者组初始化流程
消费者分区策略
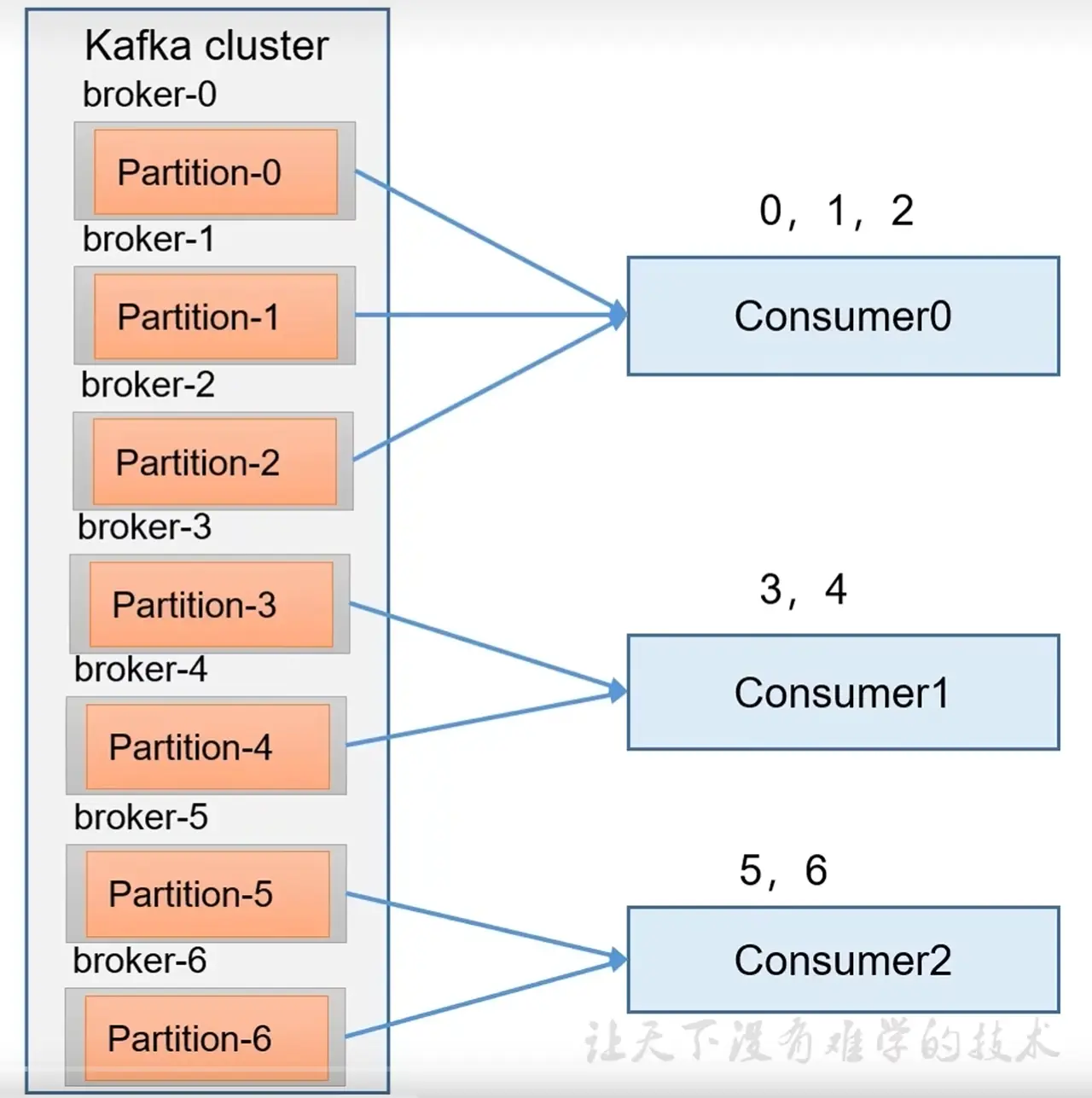
1. range 分区策略
通过 分区数/消费者数 来决定每个消费者应该消费几个分区,如果除不尽,则前面几个消费者会多消费一个分区。例如,如果有 7 个分区,3 个消费者,那么第 1 个消费者会多消费一个分区。Topic 数少还好,如果 Topic 数多会造成数据倾斜。
2. RoundRobin 分区策略
轮询分区策略,把所有的分区和所有的消费者都列出来,然后按照 hashcode 进行排序,最后轮询分配给各个消费者。
3. Sticky 分区策略
粘性分区策略,尽量均匀且随机地把各个分区分给各个消费者组
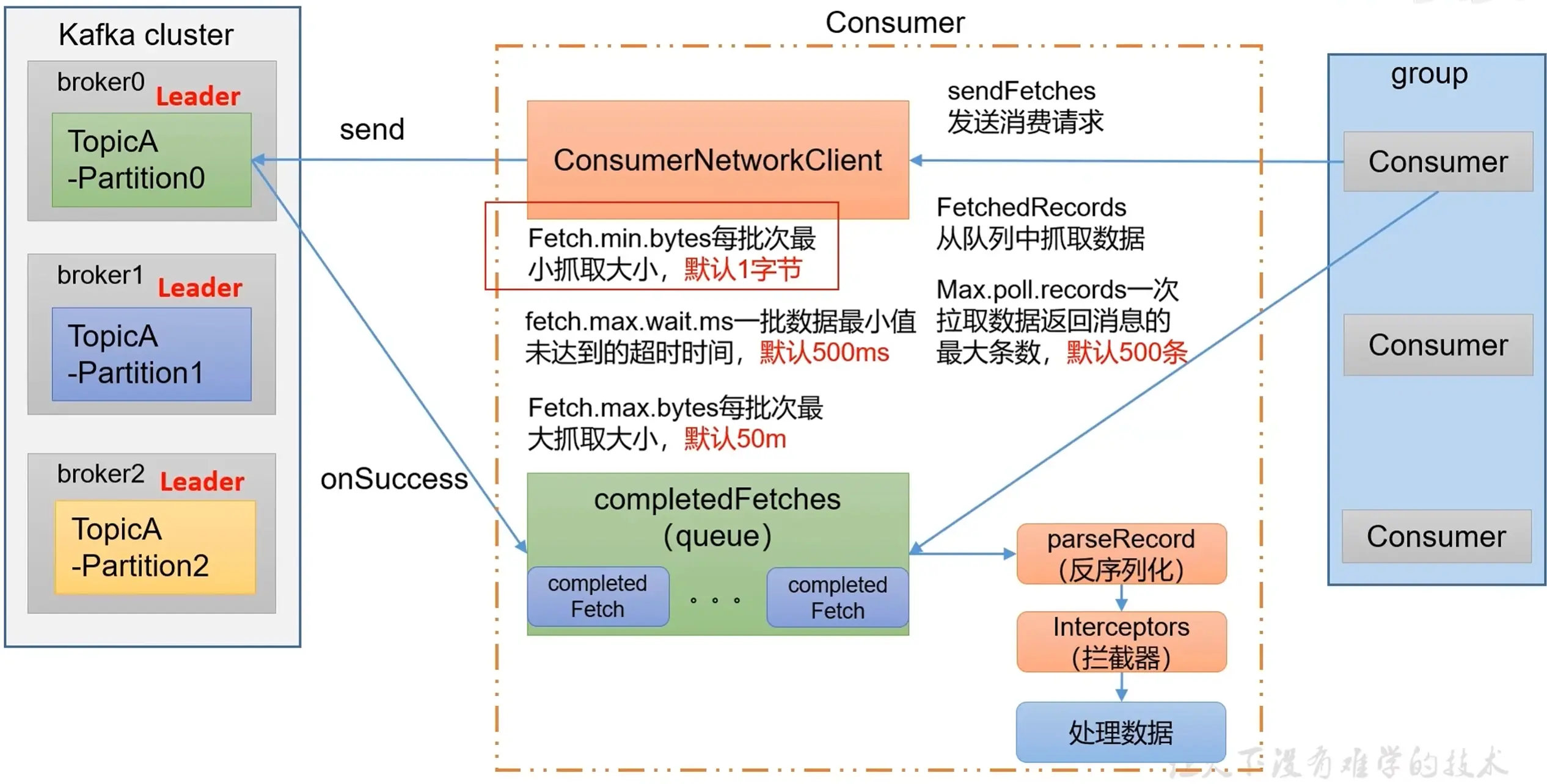
消费者工作流程
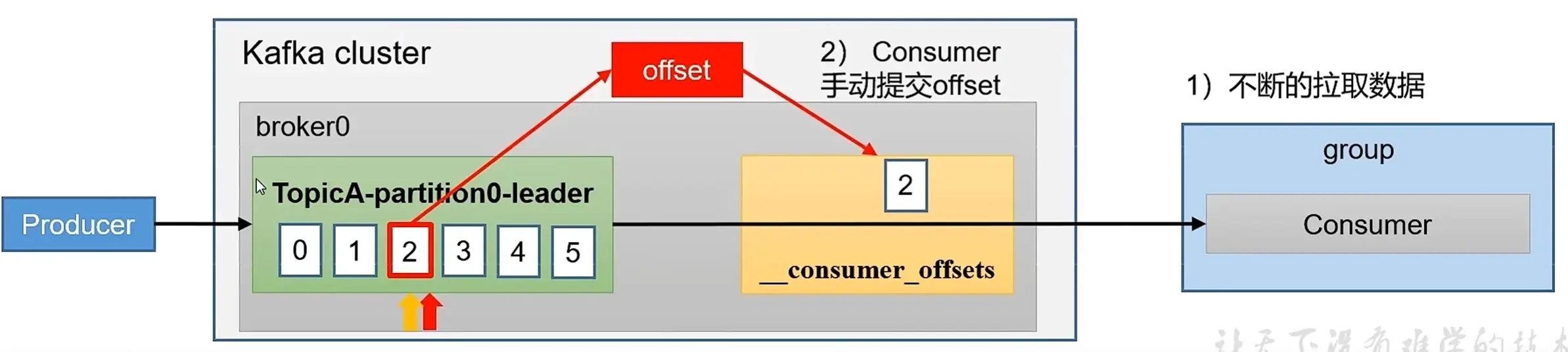
offset
offset 偏移量用来记录 Kafka 消费者的消费进度,0.9 版本之前保存在 ZK ;0.9 版本开始,默认将 offset 保存在 kafka 内置的 _consumer_offsets Topic 中。 _consumer_offsets 中采用 key 和 value 存储数据,key 是 gdoup.id + topic + 分区号,value 是 offset 的值,每隔一段时间,Kafka 内部会对这个 Topic 进行压缩(保留最新数据)
1. 自动提交 offset
enable.auto.commit用来开启自动提交 offset 功能,默认是trueauto.commit.interval.ms用来指定自动提交 offset 的时间间隔,默认是5s
2. 手动提交 offset
自动提交简单遍历,但开发人员难以把握 offset 提交的时机。Kafka 对此还提供了手动提交的方式,分为同步提交和异步提交两种实现。
- 同步提交阻塞当前线程,直到提交成功,如果提交失败则会重试
- 异步提交没有失败重试机制,有可能提交失败
java
// 手动同步提交
consumer.commitAsync();
// 手动异步提交
consumer.commitAsync();3. 指定 offset 消费
ealiest:自动将偏移量重置为最早的偏移量,从头开始消费latest(默认值):自动将偏移量重置为最新偏移量none:如果未找到消费者组的先前偏移量,则向消费者抛出异常- 指定从任意位置开始消费
java
// 指定位置进行消费
// 1. 获取分区信息
Set<TopicPartition> topicPartitions = consumer.assignment();
// 2. 保证分区已经完成
while (topicPartitions.size() == 0) {
consumer.poll(Duration.ofSeconds(1));
topicPartitions = consumer.assignment();
}
// 3. 指定从 offset 100 开始消费
for (TopicPartition topicPartition : topicPartitions) {
consumer.seek(topicPartition,100);
}4. 重复消费与漏消费
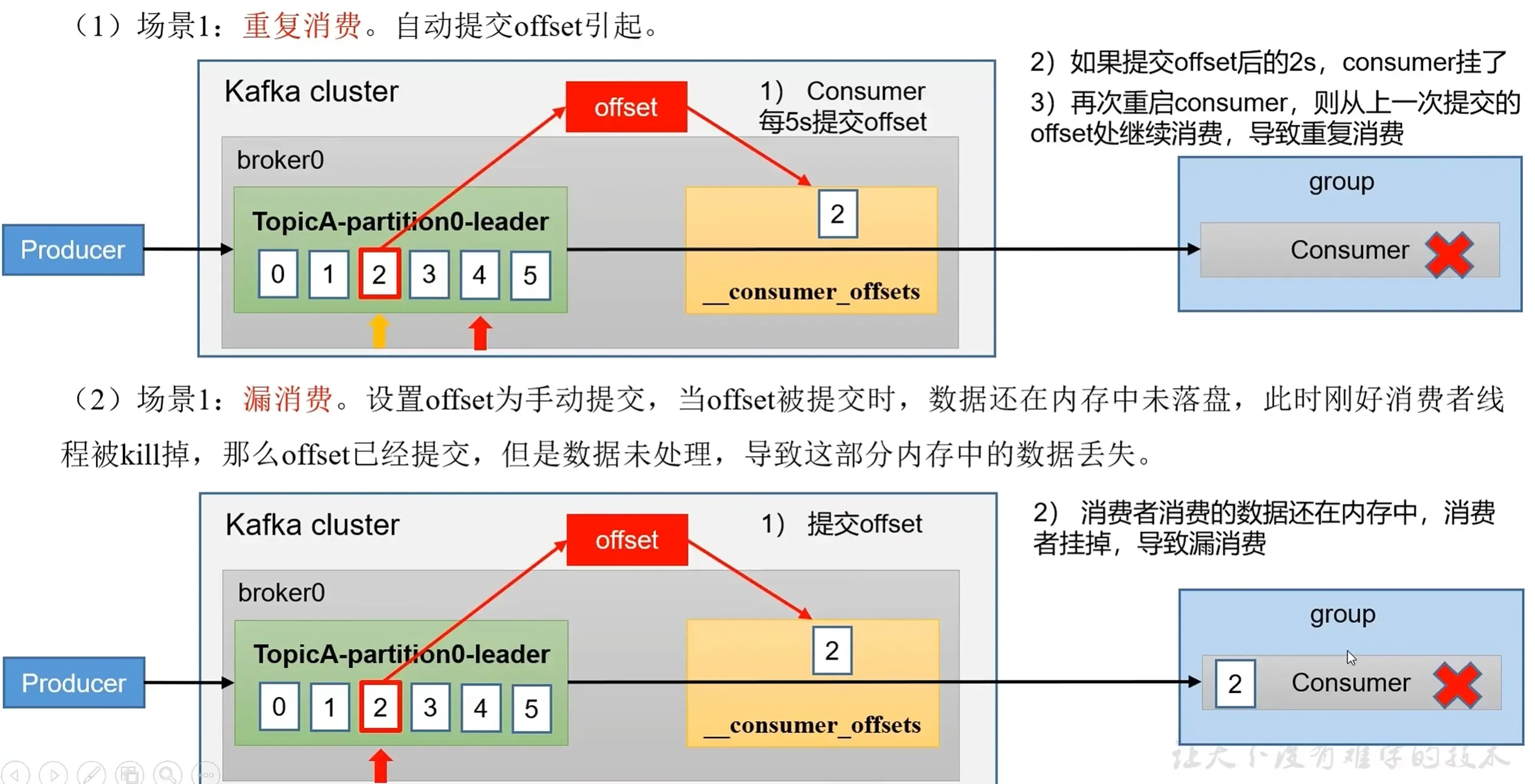
为了解决漏消费与重复消费问题,保证精准一次消费,需要消费者事务来保证。
5. 数据积压
- 如果 Kafka 消费能力不足,可以增加 Topic 的分片数,提升消费者组的消费者数量(消费者数 = 分区数)
- 如果是下游的数据处理不及时,可以提高每批次拉取的数量