Redis 数据类型
字数: 0 字 时长: 0 分钟
Redis 存储架构层级
Redis 整个结构抽象:
数据库(redisDb)➡ 字典(dict)➡ 哈希表(dictht)➡ 哈希桶(dictEntry数组)➡ 值(redisObject)1. 数据库层 redisDb
Redis 单实例默认划分为 16 个独立的数据库,以实现逻辑上的环境隔离,避免键名冲突
typedef struct redisDb {
dict *dict; // 键空间字典 存放所有键值对的入口
dict *expires; // 过期字典 记录每条 key 的存活时间
int id; // 数据库ID(0~15)
// ... 其他字段(如阻塞keys、watched keys)
} redisDb;2. 字典 dict
每个数据库有一个字典结构,字典有两个哈希表(ht[0]和ht[1]),实现渐进式 Rehash
typedef struct dict {
dictht ht[2]; // 两个哈希表(ht[0]主表,ht[1]Rehash临时表)
long rehashidx; // Rehash进度(-1表示未启动,≥0表示当前迁移到第几个桶)
unsigned long iterators;// 当前运行的迭代器数量(安全迭代用)
// ...
} dict;渐进式 Rehash 触发条件:
- 扩容:当
ht[0].used / ht[0].size > load_factor(默认负载因子为1) - 缩容:当
ht[0].used < ht[0].size / 10
渐进式 Rehash 过程:
- 分配新哈希表
ht[1]空间 - 设置
rehashidx = 0,表示 Rehash 开始 - 每次操作迁移一个桶
- 若用户进行查询操作,先去
ht[0]查找,若未找到,则去ht[1]查找 - 若用户进行新增操作,则直接写入
ht[1] rehashidx逐步增加,直到所有桶迁移完成
3. 哈希表 dictht
哈希表是承载哈希桶数组的实际容器,管理内存中的键值对分布
typedef struct dictht {
dictEntry **table; // 哈希桶数组(每个元素是链表的头节点指针)
unsigned long size; // 桶的总数量(数组长度,总为 2^n)
unsigned long sizemask; // 掩码 = size - 1(快速计算索引:hash & sizemask)
unsigned long used; // 已存储键值对的数量
} dictht;4. 哈希桶 dictEntry
typedef struct dictEntry {
void *key; // 键(指向SDS字符串)
union {
void *val; // 值(指向redisObject)
uint64_t u64;
int64_t s64;
// ... 其他数值类型
} v;
struct dictEntry *next; // 下一个Entry指针(链地址法解决冲突)
} dictEntry;5. 值对象 redisObject
统一封装 Redis 所有的值数据类型,携带 类型 、 编码 、 内存管理 和 LRU 信息
typedef struct redisObject {
unsigned type:4; // 数据类型(4位,如 OBJ_STRING、OBJ_LIST)
unsigned encoding:4; // 编码方式(4位,决定底层结构,如 REDIS_ENCODING_INT)
unsigned lru:24; // LRU时间戳或LFU计数(内存淘汰策略使用)
int refcount; // 引用计数(用于内存回收)
void *ptr; // 指向实际数据的指针(如指向sds、quicklist结构体等)
} robj;全链路示例:读取一个 Key 的过程
- 用户发起请求:
Get user:1001 - 数据库定位:根据当前 SELECT 的数据库ID,找到对应的
redisDb - 哈希表选择:
- 若未在 Rehash ,则直接在
ht[0]中查找 - 若在 Rehash ,则先在
ht[0]中查找,若未找到,则去ht[1]中查找
- 若未在 Rehash ,则直接在
- 哈希计算与桶定位:
- 对 Key
user:1001执行哈希函数,找到桶索引 index - 遍历链表(
dictEntry->next),比较每个节点的 Key 是否匹配
- 对 Key
- 获取值对象:
- 找到 Key 对应的
dictEntry,获得 Val 指针 ➡redisObject. - 根据
redisObject的type和encoding字段,决定如何解析数据 - 若
type=OBJ_STRING且encoding=OBJ_ENCODING_EMBSTR,直接读取嵌入的字符数据
- 找到 Key 对应的
- 返回结果:将值反序列化客户端协议格式并返回
String 字符串
String 类型是最基本的数据类型,一个 key 对应一个 value。String 类型是二进制安全的,Redis 的 String 可以包含任何数据,如数字、字符串、jpg图片
编码方式
int:保存有符号整数值,使用8个字节,支持64位整数embstr:保存长度小于44字节的简单动态字符串,SDS(Simple Dynamic String)raw:保存长度大于44字节的字符串;如果embstr发生修改,则直接转换为raw,无论长度是否大于44字节。
SDS 简单动态字符串
Redis 没有复用 C 语言的字符串,而是新建了字节的字符串结构 SDS ,Redis 中的所有键都是 SDS 结构
// SDS 类型(根据长度自动选择)
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 字符串实际长度(已用字节)
uint8_t alloc; // 总分配空间(不含头部和末尾的\0)
unsigned char flags; // SDS 类型标识(低 3 位)
char buf[]; // 字符数组(兼容 C 字符串)
};常用命令
| 类别 | 命令 | 说明 | 示例 |
|---|---|---|---|
| 读写 | SET key value [NX/XX] | 存值(NX:不存在才存;XX:存在才覆盖 | SET user:1001 "Alice" NX |
GET key | 取值 | GET user:1001 → "Alice" | |
| 数值增减 | INCR key | 整数值 +1 | INCR counter → 1 |
INCRBY key increment | 增加指定整数值 | INCRBY counter 5 → 6 | |
DECR key | 整数值 -1 | DECR stock → 99 | |
| 批量操作 | MSET key1 val1 key2 val2 | 批量存值 | MSET a 1 b 2 |
MGET key1 key2 | 批量取值 | MGET a b → ["1", "2"] | |
| 过期控制 | SETEX key sec value | 存值并设置秒级 TTL | SETEX otp:1001 60 "38493" |
TTL key | 查看剩余存活时间(秒) | TTL otp:1001 → 58 |
Hash 散列
Hash 是 Redis 中的 K-V 键值对结构,特别适合用来存储对象
编码方式
- zipList:压缩列表,当哈希对象键值对数量小于 512 个;所有键值对的键和值的字符串长度都小于等于 64 byte 时采用此数据结构
- hashTable:当超过上述限制时,从
zipList升级为hashTable,但不支持降级。 - listPack:Redis 7 使用
listPack替代了zipList
压缩列表 ZipList
/* 传统 ziplist entry 结构 */
typedef struct {
uint32_t prevlen; // 前一个 entry 的长度
uint32_t encoding; // 当前 entry 的编码
unsigned char contents[]; // 数据内容
} zlentry;ZipList 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,是一种经过特殊编码的双向链表,它不存储指向前一个链表节点的 prev 和指向下一个链表节点的指针 next,而是存储上一个节点长度。通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存,只用在字段个数少,字段值小的场景里面
为什么 Redis 7 使用 listPack 替代了 zipList
因为 zipList 存在连锁更新问题,是一个性能瓶颈
- 比如初始所有节点的
prevlen长度都为1个字节 - 此时在头部插入一个
长度 >= 254的大节点,导致第二个节点的prevlen扩展为5字节(后续所有节点都需要更新prevlen)
listPack 当前节点不再存储前节点长度,而是存储本节点长度解决了这个问题
常用命令
| 类别 | 命令 | 说明 | 示例 |
|---|---|---|---|
| 读写字段 | HSET key field value | 设置字段值 | HSET user:1001 name "Bob" |
HGET key field | 获取字段值 | HGET user:1001 name → "Bob" | |
| 批量操作 | HMSET key field1 val1 ... | 批量设置字段(推荐使用 HSET) | HSET user:1001 age 30 ... |
HMGET key field1 field2 | 批量获取字段 | HMGET user:1001 name age | |
| 全量操作 | HGETALL key | 获取所有字段和值 | HGETALL user:1001 → 完整哈希 |
| 原子增减 | HINCRBY key field increment | 增减数值(支持负数) | HINCRBY user:1001 age 1 → 31 |
List 列表
Redis 的 List 是一种有序的序列数据结构,支持在头尾两端高效地插入和删除元素
编码方式
- 3.2 版本之前,采用
ZipList(小数据)+LinkedList(大数据) 实现 - 3.2 版本之后,采用
QuickList实现
快表 QuickList
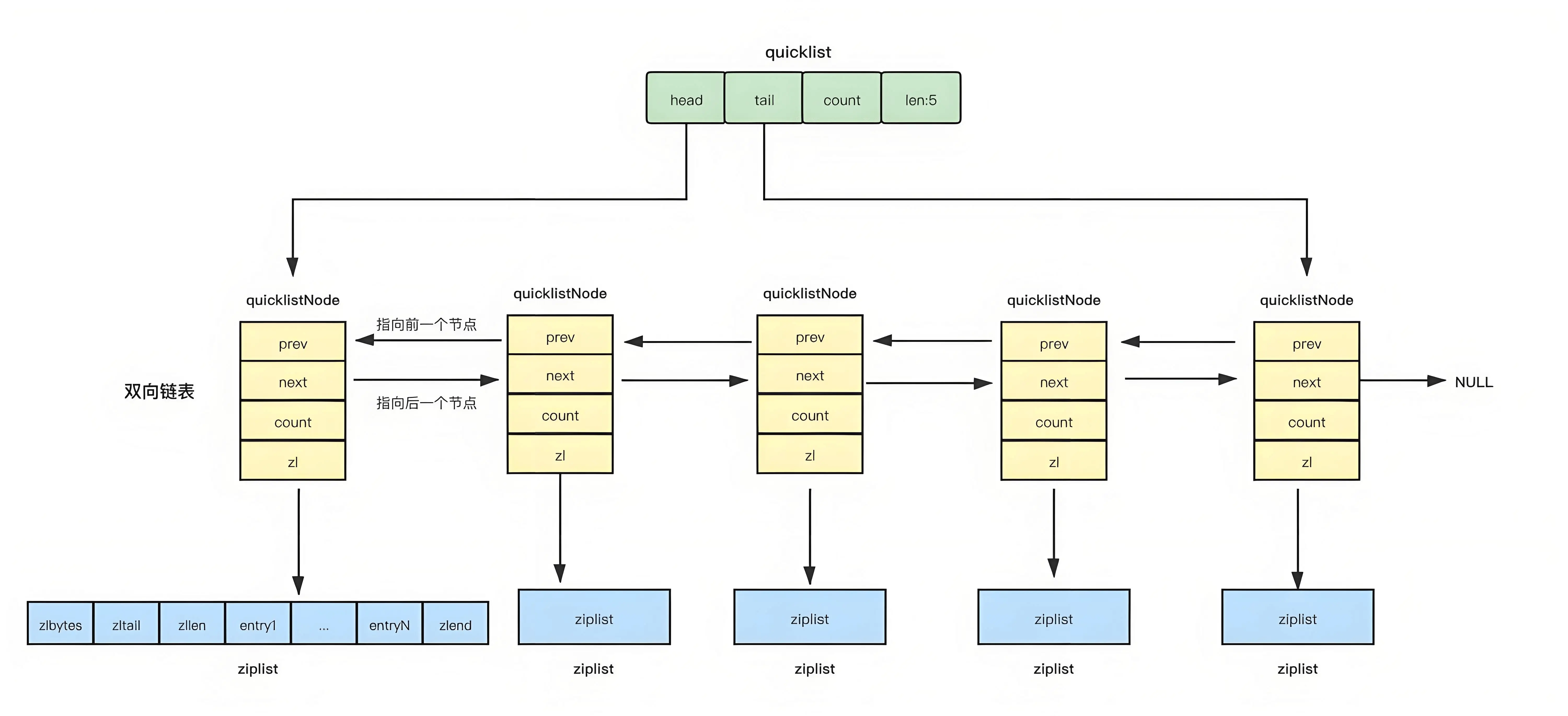
QuickList 整体结构是链表,每个节点又是压缩列表,结合了 ZipList 与 LinkedList ,平衡了内存占用和读写性能
常用命令
| 类别 | 命令 | 说明 | 示例 |
|---|---|---|---|
| 插入元素 | LPUSH key elem1 elem2 | 左插入元素 | LPUSH tasks "task1" "task2" |
RPUSH key elem1 elem2 | 右插入元素 | RPUSH log:1001 "error1" "..." | |
| 弹出元素 | LPOP key [count] | 左弹出元素(Redis 6.2+ 支持弹出多个) | LPOP tasks 2 → 弹出两个 |
RPOP key [count] | 右弹出元素 | RPOP log:1001 | |
| 范围查询 | LRANGE key start end | 范围查询(0 -1 表示全部) | LRANGE queue 0 9 |
| 阻塞弹出 | BLPOP key1 key2 timeout | 阻塞左弹出(秒级等待) | BLPOP orders 10 |
Set 集合
Set 是 Redis 中的无序且唯一集合数据结构,支持高效的集合运算(交集、并集、差集等)
编码方式
intset:集合元素都是整数,且元素个数 <=set-max-intset-entries(默认 512)hashTable:反之使用hashTable
常用命令
| 类别 | 命令 | 说明 | 示例 |
|---|---|---|---|
| 元素管理 | SADD key member1 ... | 添加元素 | SADD tags:news "AI" |
SREM key member | 删除元素 | SREM tags:news "Blockchain" | |
| 集合运算 | SINTER key1 key2 | 交集 | SINTER user:a:tags user:b:tags |
SUNION key1 key2 | 并集 | SUNION group1 group2 | |
SDIFF key1 key2 | 差集(key1 - key2) | SDIFF all_users vip_users | |
| 元素检查 | SISMEMBER key member | 检查是否存在 | SISMEMBER tags:news "AI" → 0 |
ZSet 集合
ZSet 是 Redis 中的有序且唯一的数据结构,每个元素关联一个分数 score ,通过分数进行排序
编码方式
- zipList:元素数量 <=
set-max-intset-entries(默认 128); 所有元素的长度 <= 64 byte - skipList:反之使用
skipList跳表
SkipList 跳表
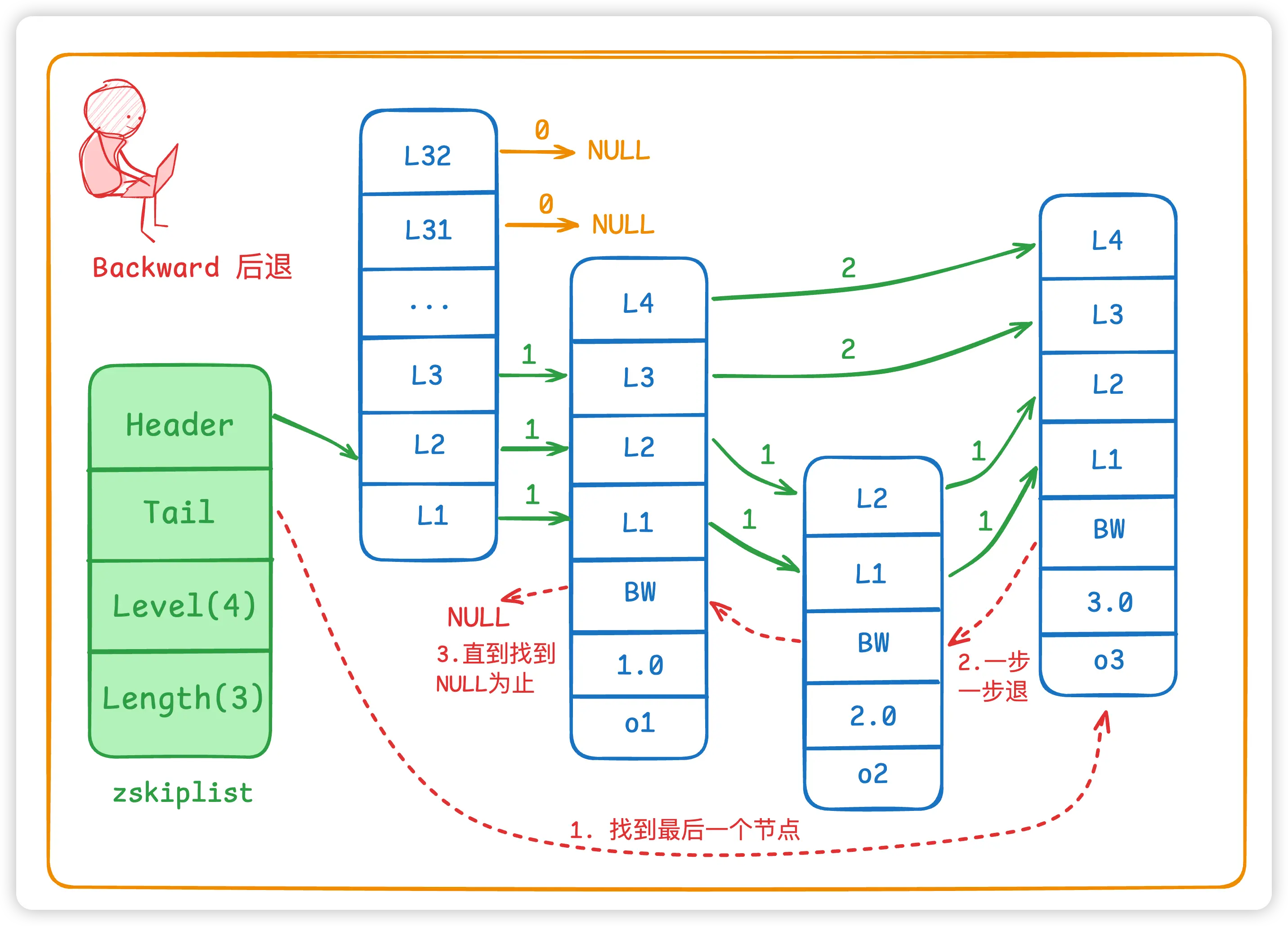
跳表是多层链表结构
- 最底层:是完整的双向链表,包含所有元素,按 score 排序
- 上层链表:指数减少节点数量(概率随机生成层数),用于加快查找速度
查找路径:
- 从高层链表开始,右向查找(若下一个节点值 <= 目标 继续,否则下探一层)
- 重复直到最底层找到目标节点或确定不存在
双向链表的时间复杂度为 O(N) , 跳表的时间复杂度最低为 O(logN)
常用命令
| 类别 | 命令 | 说明 | 示例 |
|---|---|---|---|
| 元素管理 | ZADD key score member [...] | 添加/更新元素(分数可重复,值唯一) | ZADD leaderboard 100 "user1" 90 "user2" |
| 排名查询 | ZRANGE key start end [WITHSCORES] | 升序查询(WITHSCORES 返回分数) | ZRANGE leaderboard 0 2 WITHSCORES |
ZREVRANGE ... | 降序查询 | ZREVRANGE leaderboard 0 0 | |
| 分数范围 | ZRANGEBYSCORE key min max | 查询分数介于 [min, max] 的元素 | ZRANGEBYSCORE grades 80 100 |
| 排名计算 | ZRANK key member | 获取升序排名(从 0 开始) | ZRANK leaderboard "user1" → 0 |
| Redis7新增命令 | ZMPOP numkeys key [MIN/MAX] [COUNT] | 原子弹出指定数量的最高/最低分成员 | ZMPOP 1 leaderboard MAX COUNT 2 |
Stream 流
Redis 提供的消息队列,实际应用有限(实际生产采用 MQ 中间件)
HyperLogLog 基数统计
超低内存消耗的基数统计,误差率为 0.81% ,适合做高并发基数统计,比如 UV/DAU 统计
GEO 地理位置
基于 ZSet 实现的地理位置存储与计算,适合寻找附近的商家、配送范围计算等
Bitmaps 位图
二进制位标记与统计,非常适合签到打卡、在线用户状态场景,非常节省内存空间