Producer 生产者
字数: 0 字 时长: 0 分钟
发送原理
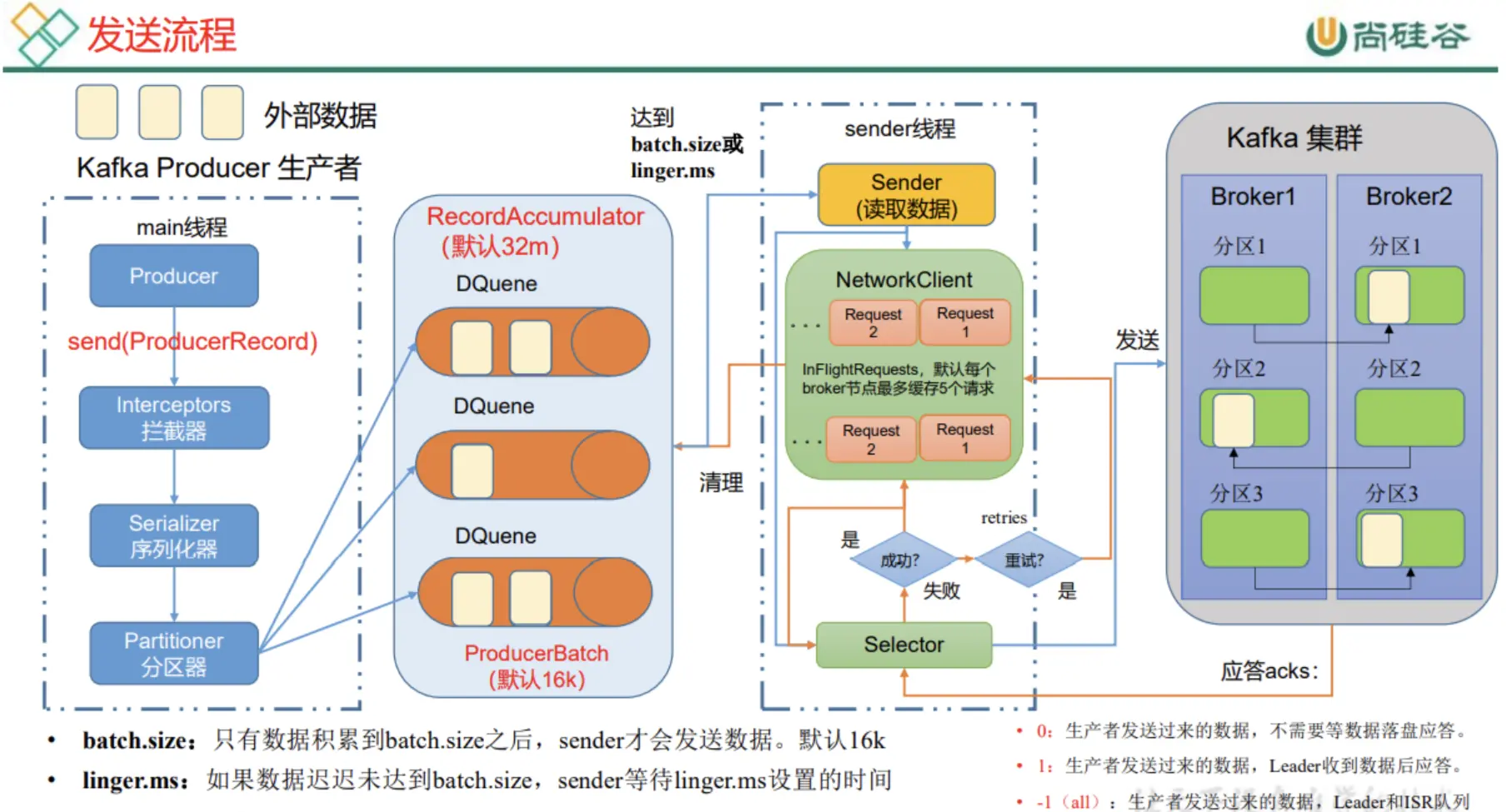
Kafka 生产者的消息发送流程中涉及两个线程,main线程和sender线程,main线程是消息的生产线程,而sender线程专门用于消息的发送。
main线程生产的消息在调用 send() 后首先会经过拦截器(实际生产很少使用),然后再经过序列化器(一般生产环境消息都是 String 类型,这里选择 Kafka 提供的 String 序列化器即可),再经过分区器发送到消息累加器中。 消息累加器维护了多个双端队列(每个队列对应一个分区)。消息在消息累加器中进行累积,达到了 batch.size 或等待 linger.ms 的时间后,触发sender 线程进行这一批数据的发送。 sender 线程有一个请求池,默认对每个 Broker 缓存 5 个请求,发送消息后,会等待服务端的 ack,如果没收到 ack 就会重试最多 retries 次,如果 ack 成功就会删除消息累加器中的消息批次,并响应给生产者。
基础实现
Properties properties = new Properties();
// 连接到 Kafka 集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
// 指定序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 创建 kafka 生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<>(properties);
// 发送消息
producer.send(new ProducerRecord<>("first","嘻嘻嘻"));发送模式
kafka 的消息发送,返回的其实是一个 Future 对象
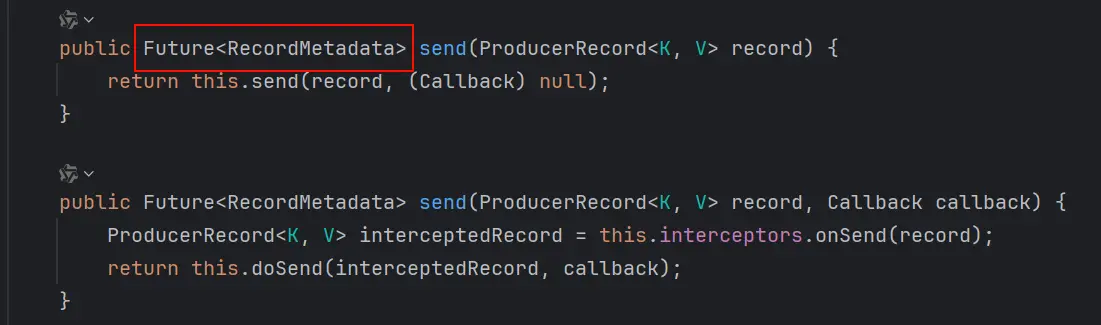
// 1. 异步发送
producer.send(new ProducerRecord<>("first","嘻嘻嘻"));
// 2. 同步发送
producer.send(new ProducerRecord<>("first","嘻嘻嘻")).get();
// 3. 异步回调 (在异步的基础上添加一个回调,是消息累积器给 producer 的回调)
producer.send(new ProducerRecord<>("first", "哈哈哈"), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 这里可以通过 recordMetadata 获取消息的元数据信息
}
});分区策略
// 1. 指明 partition 的情况,消息将直接发往 0 号分区
producer.send(new ProducerRecord<>("first", 0, "key", "hello"));
// 2. 如果没有指明分区,但有 key 的情况,则将 key 的 hash 值与
// topic 的 partition 个数取模的值作为分区值
producer.send(new ProducerRecord<>("first", "key", "hello"));
// 3. 如果没有分区和 Key,则随机选择一个分区,并尽可能一直使用该分区,
// 该分区的 batch 已满,则再随机选另一个分区(和上一个分区不同)
producer.send(new ProducerRecord<>("first", "hello"));生产者调优
默认情况下, linger.ms 的值是 0ms,表示没有延迟,即消息来一条到消息累加器中,sender 就发送一条,会产生大量的 IO 操作,因此我们可以调整 linger.ms 的值,比如 5ms,这样消息会累积 5ms,然后触发一次发送,从而减少 IO 操作,提升吞吐量。
根据实际生产情况,还可以调整 batch.size 的值,比如 32KB,这样每批消息 32KB 触发发送,从而减少 IO 操作,提升吞吐量。也可以通过 消息压缩 的方式进一步减小消息传输的网络带宽。
// 生产者吞吐量调优
// 缓冲区大小设置为 32MB
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 批次大小设置为 16KB
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
// 延迟设置为 1ms
properties.put(ProducerConfig.LINGER_MS_CONFIG,1);
// 开启压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");消息确认机制
producer 提供了三种消息确认的模式,通过配置 acks 的值来指定
0:生产者发送数据后,不需要等待数据落盘应答,丢数概率大1:生产者发送数据后,Leader 收到数据后应答,丢数概率小-1:生产者发送数据后,Leader 和 ISR 中的所有副本收到数据后应答,不会丢数
Leader 维护了一个动态的 in-sync replica set ISR,如果 Follower 长时间(默认 30s)未向 Leader 发送通信请求或同步数据,则该 Follower 将会被踢出 ISR。 如果分区副本设置为 1 个,或者 ISR 里应答的最小副本数量设置为 1 (默认为 1),那么和 acks=1 的效果一样有丢数风险
数据完全可靠条件:acks=-1 并且分区副本大于等于 2 ,然后 ISR 里应答的最小副本数量大于等于 2
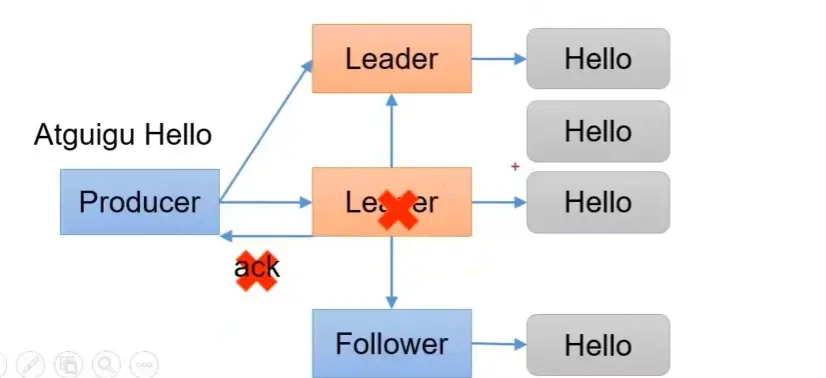
当 acks=-1 时,如果 Leader 和 ISR 中的副本节点都收集到数据后,但 Leader 在返回 acks 时挂掉了,原来的一个副本节点晋升为 Leader, Producer 再发送一份数据为新 Leader,那么新 Leader 就有两份重复的数据了。
幂等性和事务
Kafka 中有三种数据传递语义:
- 至少一次:指数据至少会成功发送一次到达 Kafka 集群,但有可能会重发(
acks=-1且ISR应答最小副本大于等于2) - 最多一次:数据最多会成功发送一次(
acks=0),数据可能会丢失 - 精确一次:数据既不能重复也不能丢失
Kafka 通过幂等性和事务来保证精确一次的语义:幂等性是指 Producer 不论向 Broker 发送多少次重复数据,Broker 都只会持久化一条,解决数据重复问题。
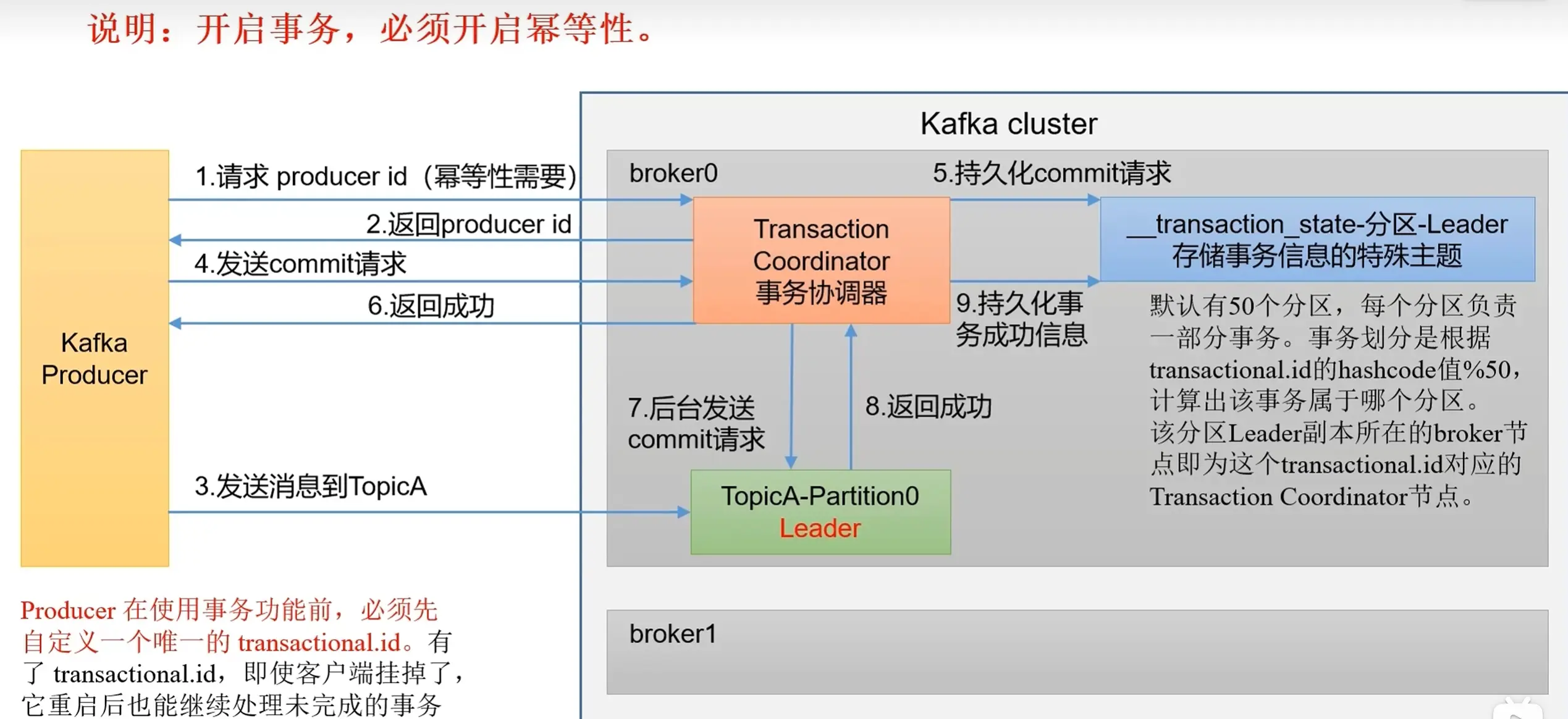
// 1. 指定事务 Id
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transaction-id");
// 2. 初始化事务
producer.initTransactions();
// 3. 开启事务
producer.beginTransaction();
try {
producer.send(new ProducerRecord<>("first", "hello"));
// 4. 提交事务
producer.commitTransaction();
}catch (Exception e) {
// 5. 回滚事务
producer.abortTransaction();
}消息有序性
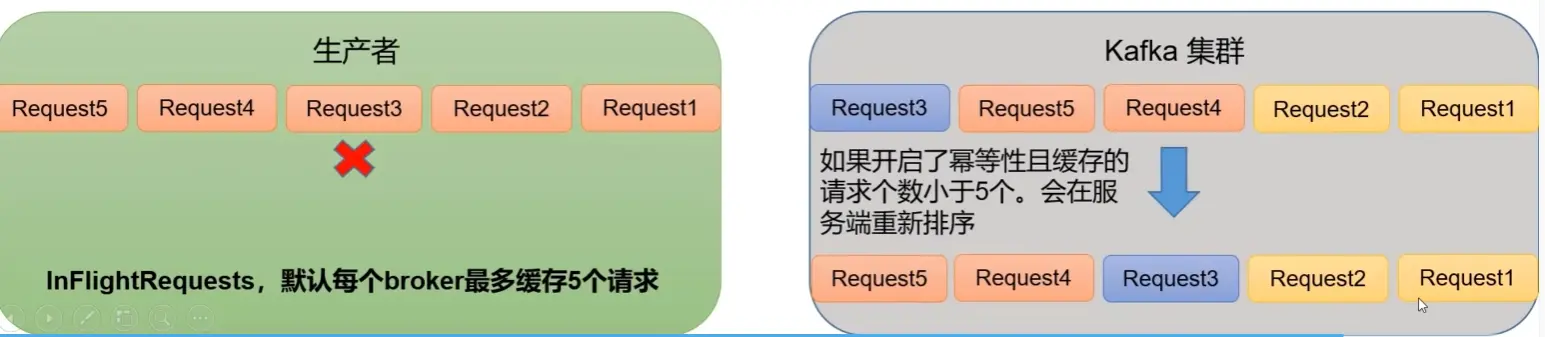
Kafka 只能保证单分区数据有序,条件如下:
- 若未开启幂等性,则
max.in.flight.requests.per.connection需要设置为1 - 若开启幂等性,则
max.in.flight.requests.per.connection需设置小于等于5
因为启动幂等后, kafka 服务端会缓存 producer 发来的最近 5 个 request 的元数据,可以保证最近 5 个 request 的数据是有序的。