Redis 进阶工程实践问题
字数: 0 字 时长: 0 分钟
禁用危险命令
模拟 redis 中有 100 万条数据
# shell 脚本
for (( i = 0; i <= 100 * 10000; i++ )); do
echo "set k$i v$i" >> /tmp/redisTest.txt;
done;
# 使用 pipe 管道批量插入 100 万数据
cat /tmp/redisTest.txt | redis-cli -h 127.0.0.1 -p 6379 -a 123456 --pipe生成环境禁用 key *,耗时太久阻塞线程
生产上配置进行禁用 keys * 、 flushdb 、 flushall 等危险命令,避免误操作
redis.conf配置文件
# 禁用 危险命令
rename-command flushall ""
rename-command keys ""
rename-command flushdb ""
Big Key 问题
参考《阿里云 Redis 开发规范》,拒绝 bigkey:

- 排查
bigkey
如果实际中出现了 bigkey,可以使用 redis-cli --bigkeys 命令排查
排查
bigkey示例
redis-cli -h 127.0.0.1 -p 6379 -a 123456 --bigkeys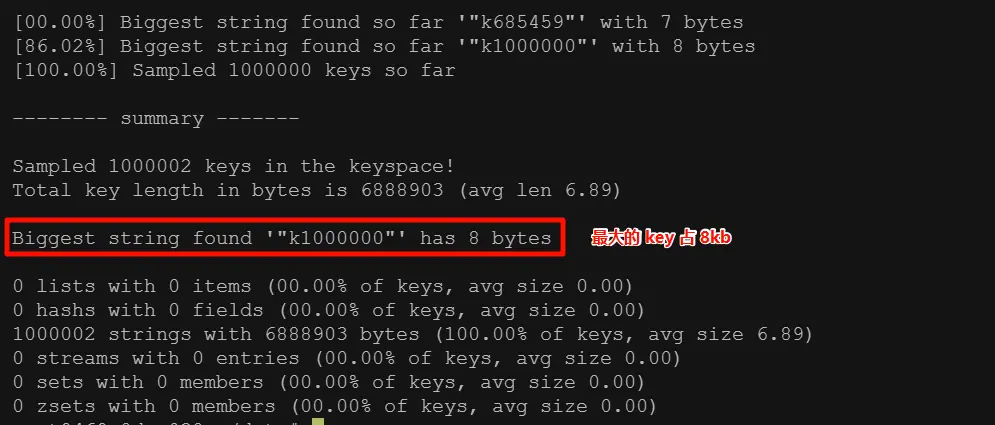
- 删除
bigkey
非字符串的 bigkey 不要使用 del 删除,使用 hscan、sscan、zscan 方式渐进式删除,同时要防止 bigkey 过期时间自动删除问题 (例如一个 200 万的 zset 过期后,会触发 del 操作,造成阻塞,而且该操作不会出现在慢查询中)
redis 4.0 引入了 Lazy Free(惰性删除)异步删除机制,将耗时删除操作交给后台线程执行,避免阻塞主线程
# redis.conf 配置文件
# 启用所有Lazy Free场景(生产环境推荐)
lazyfree-lazy-eviction yes # 内存淘汰时异步删除
lazyfree-lazy-expire yes # 过期Key异步删除
lazyfree-lazy-server-del yes # 命令隐式删除时异步处理
replica-lazy-flush yes # 从节点接受FLUSHALL时异步清空缓存双写一致性
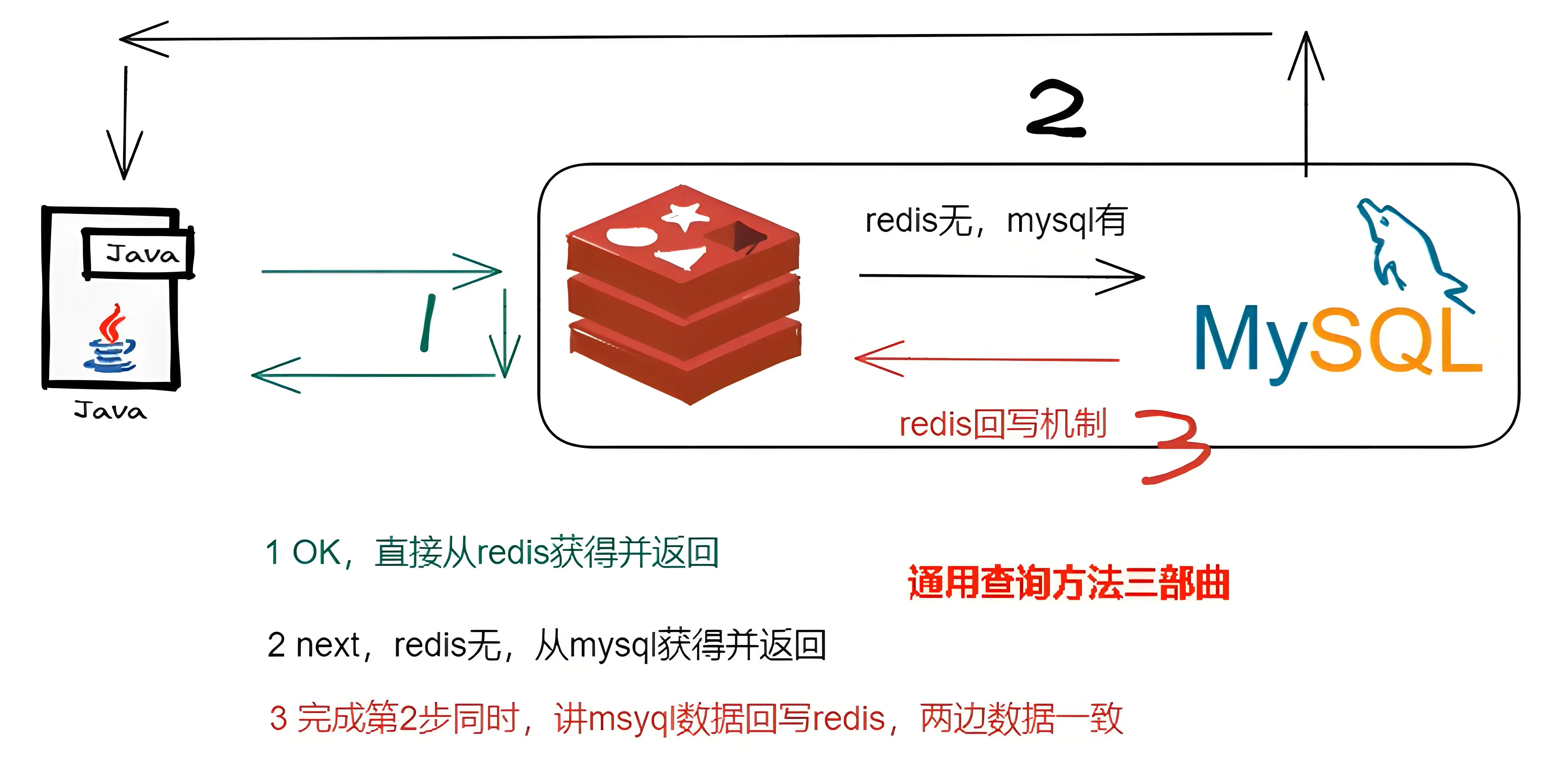
当数据同时存在于 持久层 和 缓存层时,两种存储的更新顺序或策略不当会导致:
- 不一致问题:客户端可能读取到过期的旧值
- 数据污染问题:高并发情况下,错误顺序更新甚至会导致持久化数据错误
并发写冲突示例
时间点 | 操作线程A | 操作线程B
-----------------------------------------------------------
T1 | 写DB(订单金额 → 120) |
T2 | | 写DB(订单金额 → 80)
T3 | 更新缓存失败(网络抖动) |
T4 | | 更新缓存成功(缓存=80)
T5 | 缓存自动重试更新 → 120 |最终结果:
- DB = 80 (B线程覆盖了A线程的DB写)
- 缓存 = 120 (A线程的缓存重新覆盖了B线程的缓存写)
- 数据永久不一致 💥
延迟双删
延迟双删就是先去删除缓存旧数据,延迟一段时间后再去删除一次缓存数据,具体流程如下:
- 线程 A 一来就去删除缓存旧数据,避免旧数据被读取
- 线程 A 更新数据库过程中
- 假如与此同时线程 B 又来更新数据库并回写缓存
- 线程 A 延迟一段时间后再去删除 B 回写缓存的数据
这样一来线程 A 延迟这段时间就得大于线程B更新数据库并回写缓存的时间,这个延迟时间不好确定
延时双删是一种业内公认可行的方案,不过也不能彻底解决问题(分布式的核心问题不保证强一致性,只保证最终一致性)。只是减少了脏数据风险,在高并发场景下,仍然有可能在线程 B 回写完成和删除前这个时间段发生脏读情况。
public void updateUserWithDelayDelete(User user) {
// Step 0. 第一次删除(防止旧数据被读取)
redis.del("user:" + user.getId());
// Step 1. 更新数据库
userDAO.update(user);
// Step 2. 延迟删除
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(500); // 可动态调整睡眠时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
redis.del("user:" + user.getId());
}, retryExecutor);
}canal 同步
也可以利用第三方组件来解决缓存双写一致性问题,比如 canal,canal 是阿里开源的组件,参考 MySQL 主从复制中的数据同步机制来对 MySQL 数据进行同步
Mysql 主从复制步骤
- 当
master上的数据发生改变时,会将其改变写入到二进制事件日志文件中,也就是binlog slave会监听binlog文件,如果binlog发生改变会发送一个I/O Thead请求二进制事件日志- 同时
master为每个I/O Thread启动一个dump Thread,用于向其发送二进制事件日志 slave根据二进制事件日志,更新数据,使得数据和master一致
canal 工作原理
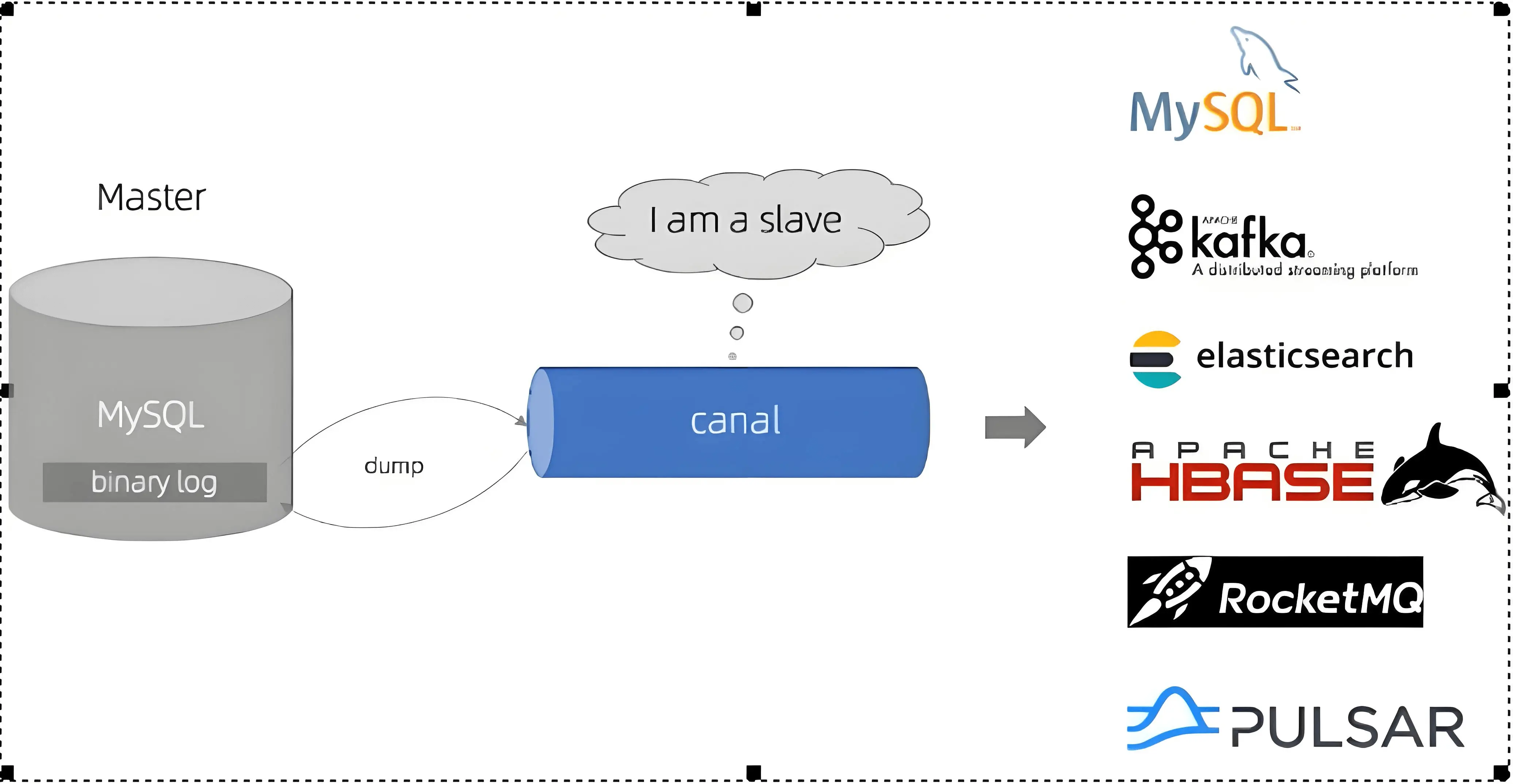
- canal 模拟 MySQL 的
slave,向 Mysqlmaster发送dump协议 - Mysql
master收到dump请求,开始推送binlog给 canal - canal 解析
binlog对象(byte流)
canal 监听 binlog 更新缓存伪代码
// Canal监听数据库变更事件(伪代码)
@CanalEventListener
public class BinlogListener {
private RedisClient redis;
// 监听用户表更新事件
@ListenPoint(
table = {"user_table"},
eventType = {EventType.UPDATE}
)
public void onUserUpdate(EventData eventData) {
Map<String, String> afterData = eventData.getAfterColumnsMap();
String userId = afterData.get("id");
// 异步更新缓存(例如放入消息队列)
mqProducer.send("cache_update_queue", "user:" + userId);
}
}布隆过滤器
布隆过滤器由一个 位数组 和 K 个独立的哈希函数 组成。添加元素时,通过 K 个哈希函数将元素映射到位数组的 K 个位置上,将这些位置的值置为 1
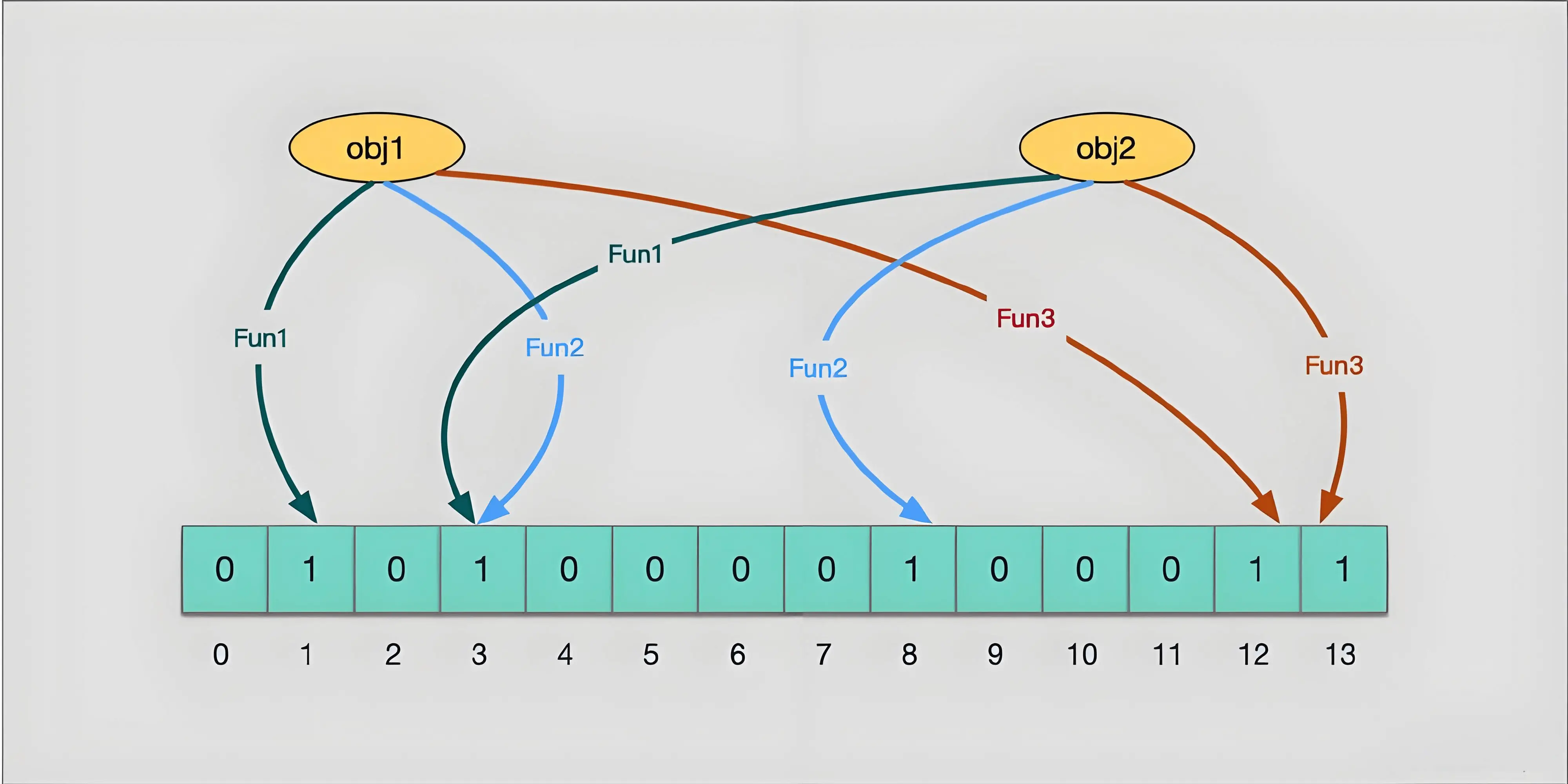
它可以判断一个元素肯定不存在,但不能判断一个元素肯定存在(当 obj1 和 obj2 的 hash 冲突,比如都存放在 1 3 5 中时,这个时候会误判 obj1 和 obk2 都存在,哪怕实际只有一个存在)
- 布隆过滤器可以添加元素,但是不能删除元素,删掉元素会导致误判率增加
- 使用时最好不要让实际元素数量远大于初始化数量,尽量一次给够容量,避免扩容
- 当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add
使用 Redis 实现布隆过滤器
可以使用 Redis 的位图(Bitmap)或 Redis 模块 RedisBloom :
java 利用 bitmap 实现布隆过滤器示例
import redis.clients.jedis.Jedis;
import java.nio.charset.StandardCharsets;
import java.util.BitSet;
import java.util.List;
import java.util.ArrayList;
public class RedisBloomFilter {
private static final String BLOOM_FILTER_KEY = "bloom_filter";
private static final int BITMAP_SIZE = 1000000; // 位图大小
private static final int[] HASH_SEEDS = {3, 5, 7, 11, 13, 17}; // 多个哈希函数的种子
private Jedis jedis;
private List<SimpleHash> hashFunctions;
public RedisBloomFilter() {
this.jedis = new Jedis("localhost", 6379);
this.hashFunctions = new ArrayList<>();
for (int seed : HASH_SEEDS) {
hashFunctions.add(new SimpleHash(BITMAP_SIZE, seed));
}
}
// 添加元素到布隆过滤器
public void add(String value) {
for (SimpleHash hashFunction : hashFunctions) {
jedis.setbit(BLOOM_FILTER_KEY, hashFunction.hash(value), true);
}
}
// 检查元素是否可能存在于布隆过滤器中
public boolean mightContain(String value) {
for (SimpleHash hashFunction : hashFunctions) {
if (!jedis.getbit(BLOOM_FILTER_KEY, hashFunction.hash(value))) {
return false;
}
}
return true;
}
// 关闭连接
public void close() {
jedis.close();
}
// 简单哈希函数
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
byte[] bytes = value.getBytes(StandardCharsets.UTF_8);
for (byte b : bytes) {
result = seed * result + b;
}
return (cap - 1) & result;
}
}
public static void main(String[] args) {
RedisBloomFilter bloomFilter = new RedisBloomFilter();
// 添加元素到布隆过滤器
bloomFilter.add("user1");
bloomFilter.add("user2");
bloomFilter.add("user3");
// 检查元素是否可能存在
System.out.println("Does user1 exist? " + bloomFilter.mightContain("user1")); // 输出: true
System.out.println("Does user4 exist? " + bloomFilter.mightContain("user4")); // 输出: false
// 关闭连接
bloomFilter.close();
}
}RedisBloom 模块
Redis 官方提供了 RedisBloom 插件,简化了布隆过滤器的实现,提供了更好的性能和更少的误判率控制
- 创建布隆过滤器
BF.RESERVE myBloomFilter 0.01 1000000- 添加元素
BF.ADD myBloomFilter "item1"- 检查元素是否存在
BF.EXISTS myBloomFilter "item1" # 返回 1(可能存在)
BF.EXISTS myBloomFilter "item2" # 返回 0(一定不存在)布隆过滤器适用场景
- 爬虫:对已经爬取过的海量 URL 去重
- 黑名单:反垃圾邮件用于判断一个邮件是否在黑名单中,提高垃圾邮件过滤的效率(可能误杀)
- 分布式系统:用于判断数据是否在某个节点上,减少网络请求,提高系统性能
- 推荐系统:用于判断用户是否已经看过某个推荐内容,避免重复推荐
缓存预热
Mysql 中有 1000 条基底数据,正常情况下第一个查询的用户会去查 mysql 然后回写给 redis,为了提升初次访问的用户体验可以提前将基底数据存入 redis ,这称为缓存预热
缓存雪崩
缓存雪崩指大量缓存在同一时间过期或失效,导致大量请求同时发起到数据库,导致数据库压力过大被压垮
解决方法:
- 永不过期:热点数据设置为永不过期 或 随机过期(加上一个随机时间)
- 熔断降级:Hystrix 或 Sentinel 限流降级,数据库压力过大时拒绝请求
- 多级缓存:本地缓存 + 分布式缓存
缓存穿透
缓存穿透指查询根本不存在的数据,数据永远都不会回写到缓存层,缓存形同虚设
解决方法:
- 回写增强:即使数据库查询为空,也回写一个缺省值(零 或 null 等)到缓存层
- 布隆过滤器:布隆过滤器可以判断缓存中是否包含该元素(如果有,可能有;如果没有,一定没有)
缓存击穿
缓存击穿指热点Key过期失效,导致大量请求直接发起到数据库
解决方法:
- 永不过期:热点数据设置为永不过期
- 互斥锁:当热点 Key 过期时,只允许一个线程去查询数据库,然后回写回缓存,其他线程就又可以继续从缓存查询数据了
- 热点预热:在 Redis 访问高峰期,提前调整热点 Key 的过期时间
热点 Key 问题
Redis 中的热点 key 可能被频繁访问,导致 Redis 的压力过大,进而影响整体性能甚至导致集群节点故障。
解决方法:
- 热点 Key 拆分:将热点数据分散到多个 Key 中,例如:通过引入随机前缀,使不同用户请求分散到多个 Key,多个 Key 分布在不同实例中,避免访问单一 Redis 实例
- 多级缓存:在 Redis 前增加其他缓存层(如 CDN、本地缓存),以分担 Redis 的压力
- 读写分离:Redis 主从架构,将读请求分发到多个节点
- 限流和降级:热点 Key 访问量过大时,应用限流策略,必要时进行服务降级(如返回空值)
Lua 脚本
Lua (葡萄牙语月亮的意思)是一种轻量级、高性能的嵌入式脚本语言。其设计目标是 简洁性、可嵌入性 和 高效率 ,常用于对性能要求较高的场景。
Redis 调用 Lua 脚本通过 eval 命令保证代码执行的原子性,直接用 return 返回脚本执行结果
Lua 脚本将三个操作拼接为一个原子操作
EVAL "脚本内容" [keys数量] [keys...] [argv...]
# 示例:实现原子性递增并设置过期时间
eval "
local current = redis.call('get', KEYS[1])
current = tonumber(current) or 0
current = current + tonumber(ARGV[1])
redis.call('set', KEYS[1], current)
redis.call('expire', KEYS[1], ARGV[2])
return current
" 1 counter 5 60Redis 实现分布式锁
如果基于 Redis 来实现分布式锁,首先需要有过期机制,否则某个客户端获取锁后宕机,永远无法释放锁,如果没有锁过期机制其他客户端永远都无法获取锁。
因此加锁可以使用 set ex nx 命令完成,即 set nx (Set if Not eXists,如果 key 不存在才设置它的值)的基础上添加了 ex 过期时间,由 Redis 保证原子性
set lock_key uniqueValue EX expire_time NX这里锁对应的 value 必须是每个客户端的唯一值,否则有可能导致别的客户端释放了自己的锁:
- 客户端 1 加锁成功,执行业务逻辑,锁过期但业务未执行完
- 客户端 2 加锁成功,执行业务逻辑中
- 客户端 1 业务执行完毕,执行释放锁操作
- 客户端 2 一脸懵逼,自己的业务逻辑没执行完锁被客户端 1 释放了
释放锁的逻辑需要先判断锁的值和唯一标识是否一致,一致后再删除释放锁,这里需要两步操作,需要使用 lua 脚本保证原子性:
if redis.call("GET",KEYS[1]) == ARGV[1]
then
return redis.call("DEL",KEYS[1])
else
return 0
endRedLock 红锁
单台 Redis 实现分布式锁存在单点故障问题,比如主从读写分离架构:
- 一个客户端在主节点上加锁成功,但是主节点突然宕机
- 此时由于主从同步延迟,从节点上还没同步到这步锁
- 从节点晋升为新的主节点,其他客户端在新主节点上加锁成功
- 此时导致两个客户端都抢到锁!!!
因此 Redis 官方推出 RedLock 分布式锁算法,适用于 Redis 集群环境,实现原理:
- 官方推荐至少部署 5 个实例,这 5 个实例之间可以没有任何关系(不同于
cluster,它们之间不需要信息交互) - 客户端会对这 5 个实例依次申请锁,如果最终申请成功的数量超过半数(
>= 3),则表明红锁申请成功。 - 如果一台实例宕机对红锁没有任何影响,因为理论上可以申请成功的实例数量为 4 ,超过了半数
红锁一定安全吗?
红锁不是绝对安全的,在极端情况下依然可能出现问题,比如:
- 客户端 1 抢到了红锁,但此时发生了 GC ,暂停(STW)了很久,GC 结束的同时,锁过期了
- 但客户端 1 认为自己还持有锁,正常执行后续逻辑(此时锁已经过期)
- 而在其他客户端看来,客户端 1 的锁已经过期,客户端 2 抢到锁,也开始执行业务逻辑
红锁的实现成本较高,而且需要依次加锁,性能不如单实例的 Redis 分布式锁,而且极端环境依然存在安全问题,因此业务上一般还是采用主从 + 哨兵模式实现分布式锁
Redisson 分布式锁
Redisson 是一个 Java 语言的 Redis 封装,提供了丰富的分布式锁实现,如:
- 加锁
Redisson 使用 Lua 脚本,利用 exists + hexists + hincrby 命令来保证只有一个线程能成功设置键(获取锁):
- 若锁不存在,则新增锁,并设置锁重入计数为 1 ,且设置锁过期时间
- 若锁存在,且唯一标识(线程ID相关)也匹配,则当前加锁请求为锁的重入请求,哈希的重入计数 +1 ,并再次设置锁过期时间
- 若锁存在,但唯一标识不匹配,说明当前锁正被其他线程占用,返回锁剩余过期时间
pttl
Redisson 加锁源码
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return commandExecutor.syncedEval(getRawName(), LongCodec.INSTANCE, command,
"if ((redis.call('exists', KEYS[1]) == 0) " +
"or (redis.call('hexists', KEYS[1], ARGV[2]) == 1)) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}- 释放锁
Redisson 释放锁源码
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" + // 若锁不存在,直接返回,不需要解锁
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " + //若锁存在,且唯一标识也匹配,计数 -1
"if (counter > 0) then " + // 如果此时计数还大于 0 ,再次设置锁过期时间
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " + // 如果计数 <= 0,则删除 key
"redis.call('publish', KEYS[2], ARGV[1]); " + // 通过广播通知其他等待锁的线程,锁已释放
"return 1; " +
"end; " +
"return nil;",
Arrays.asList(getRawName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
}Redisson 看门狗机制
看门狗(watch dog)机制主要用来避免 Redis 中的锁在超时后业务逻辑还未执行完毕,锁被自动释放的情况。(通过定期刷新锁的过期时间来实现自动续期)
看门狗自动续期锁源码
// 续期锁的过期时间
private void renewExpiration() {
// 从过期续期映射中获取锁的过期条目
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return; // 如果找不到条目,说明没有锁需要续期
}
// 创建一个定时任务,用于定期续期锁的过期时间
Timeout task = commandExecutor.getServiceManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 重新获取过期条目
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return; // 如果条目已被移除,结束任务
}
// 获取持有锁的线程 ID
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return; // 如果没有线程 ID,说明没有线程持有该锁,结束任务
}
// 异步续期锁的过期时间
CompletionStage<Boolean> future = renewExpirationAsync(threadId);
future.whenComplete((res, e) -> {
if (e != null) {
// 如果续期过程中发生错误,记录日志并移除续期条目
log.error("Can't update lock {} expiration", getRawName(), e);
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
return;
}
if (res) {
// 如果续期成功,重新调度续期任务
renewExpiration();
} else {
// 如果续期失败,取消续期操作
cancelExpirationRenewal(null);
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS); // 定时任务每 internalLockLeaseTime / 3 毫秒执行一次
// 设置定时任务到过期条目中
ee.setTimeout(task);
}
// 启动续期操作,首次获取锁时会调用此方法
protected void scheduleExpirationRenewal(long threadId) {
// 创建新的过期条目
ExpirationEntry entry = new ExpirationEntry();
// 尝试将新的条目加入到续期映射中
ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);
if (oldEntry != null) {
// 如果条目已存在,说明已有其他线程在续期,添加当前线程 ID 到条目中
oldEntry.addThreadId(threadId);
} else {
// 如果是首次添加,开始进行续期操作
entry.addThreadId(threadId);
try {
// 启动锁过期续期任务
renewExpiration();
} finally {
// 如果当前线程被中断,取消续期操作
if (Thread.currentThread().isInterrupted()) {
cancelExpirationRenewal(threadId);
}
}
}
}使用 Redis 实现排行榜
使用 Redis 的 Zset 类型可以快速高效地实现排行榜:
- 存储分数和成员:使用
zadd命令,如zadd leaderbord 1000 user1存储user1d的分数为1000 - 获取排名:使用
zrank命令,如zrank leaderbord user1返回user1的排名 - 获取前 N 名:使用
zrevrange命令,如zrevrange leaderbord 0 4获取前 5 名用户及其分数 - 更新分数:使用
zincrby命令对分数进行加减操作,如zincrby leaderbord -100 user1将user1分数减100